





大数据处理之倒排索引原理:
如果使用一个矩阵来描述词语和文档之间的关系,不难得出如下“矩阵”。其中,每一列代表一个文档,每一行代表一个词语,每一个单元格代表“此文档中出现此词语的次数”。
一、词语和文档的关系:
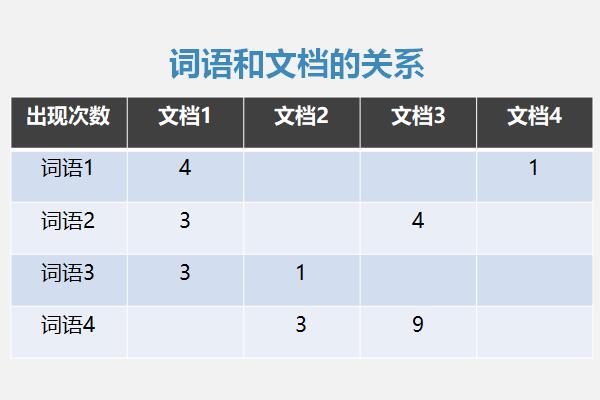
矩阵中的第一列说明“在文档1中,词语1出现了4次、词语2和词语3均出现了3次,并且文档1中不再有其他词语出现”。同理,矩阵中的第一行则说明“词语1在文档1中出现在4次,在文档4中出现1次,在其他文档中不出现”。其他行列同理。
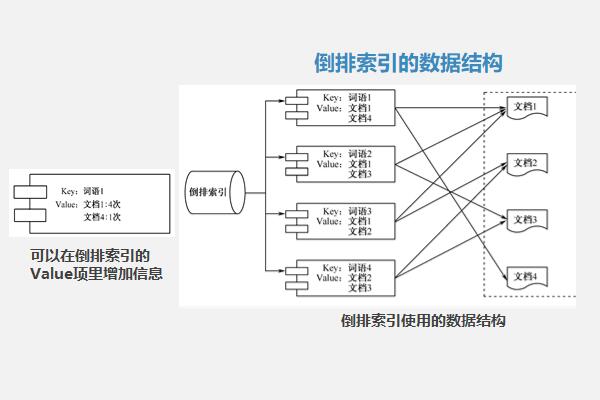
二、倒排索引的数据结构:
倒排索引可以使用这样一个Map来实现:每一个词语都是Map中的一个键(Key),这个键对应的Value是一个集合,里面保存着包含这个词语的文档的编号。存储形式为:Map< String key, Set< Struct< DocID > value > >。
同理,如果要在倒排索引中加入更多信息,可以在Value中增加记录项目。
三、倒排索引的建立实例:
假设现在有两篇文档,每篇文档的内容如下:

其建立实例的步骤如下:
1.文章本分词
2.去除无关词语
3.词语归一化
4.建立词语-文档矩阵
5.建立到排索引
四、倒排索引的更新策略:
1、完全重建策略
先进行“文档暂存”,待文档暂存区达到一定数量后,对所有文档重新建立索引。
2、再合并策略
新文档会立即被解析,解析结果会进行“索引暂存”,待索引暂存区达到一定数量后,再将新旧索引合并。
3、原地更新策略
新文档立刻被解析,解析结果立刻被加入旧索引中。
4、混合策略
其思想是混合地使用上述几种策略,取长补短,以达到最好的性能。

























 备案:
备案: