





句法理论与自动分析:
依存语法 (Dependency Parsing, DP) 往往是一种基于规则的专家系统,通过分析语言单位内成分之间的依存关系揭示其句法结构。直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系,往往最终生成的结果,是一棵句法分析树。句法分析可以解决传统词袋模型不考虑上下文的问题。仍然是上面的例子,其分析结果如下图9-1所示。
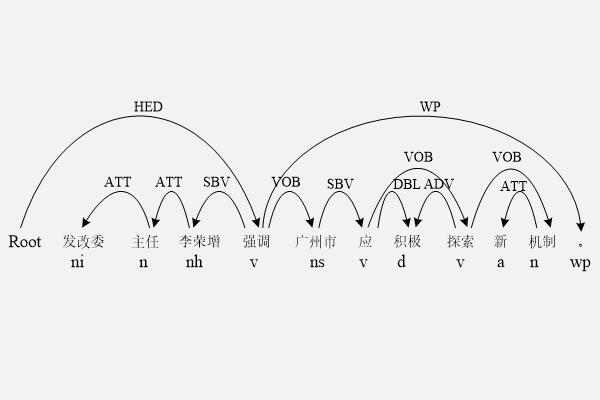
从分析的结果中我们可以看到,句子的核心谓词为“强调”,而不是“增强”,主语是“李荣增”而不是“李荣”,宾语是“广州市应积极...”,“发改文主任”是李荣增的定语。有了上面的句法分析结果,我们就可以比较容易的看到,“强调者”是“李荣增”,而强调的内容是“广州市应积极...”。
依存语法本质上研究词和词之间的依存关系。一个依存关系连接两个词,分别是核心词(head)和依存词(dependent)。目前主要采用研究主要集中在基于数据驱动的依存句法分析方法,即在训练实例集合上学习得到依存句法分析器,而不涉及依存语法理论的研究
基于图的依存句法分析方法。基于图的方法将依存句法分析问题看成从完全有向图中寻找最大生成树的问题。一棵依存树的分值由构成依存树的几种子树的分值累加得到。根据依存树分值中包含的子树的复杂度,基于图的依存分析模型可以简单区分为一阶和高阶模型。 基于图的方法通常采用基于动态规划的解码算法,也有一些学者采用柱搜索(beam search)来提高效率。学习特征权重时,通常采用在线训练算法,如平均感知器(averaged perceptron)。
基于转移的依存句法分析方法。基于转移的方法将依存树的构成过程建模为一个动作序列,将依存分析问题转化为寻找最优动作序列的问题。早期,研究者们使用局部分类器(如支持向量机等)决定下一个动作。近年来,研究者们采用全局线性模型来决定下一个动作,一个依存树的分值由其对应的动作序列中每一个动作的分值累加得到。特征表示方面,基于转移的方法可以充分利用已形成的子树信息,从而形成丰富的特征,以指导模型决策下一个动作。模型通过贪心搜索或者柱搜索等解码算法找到近似最优的依存树。和基于图的方法类似,基于转移的方法通常也采用在线训练算法学习特征权重。
多模型融合的依存句法分析方法。基于图和基于转移的方法从不同的角度解决问题,各有优势。基于图的模型进行全局搜索但只能利用有限的子树特征,而基于转移的模型搜索空间有限但可以充分利用已构成的子树信息构成丰富的特征。因此,研究者们使用不同的方法融合两种模型的优势,常见的方法有:stacked learning;对多个模型的结果加权后重新解码(re-parsing);从训练语料中多次抽样训练多个模型(bagging),取得了较好的效果。

























 备案:
备案: