





语言模型的平滑方法:
Add-one是最简单、最直观的一种平滑算法。既然希望没有出现过的n-Gram的概率不再是0,那就不妨规定任何一个n-Gram在训练语料至少出现一次(即规定没有出现过的n-Gram在训练语料中出现了一次),对于unigram模型而言,Add-one模型可由式(6)计算得来,其中,M是训练语料中所有的n-Gram的数量,而v 是所有的可能的不同的n-Gram的数量。同理,对于bi-gram模型而言,可得 由式(7)得来;推而广之,对于n-Gram模型而言,可由式(8)计算而来。
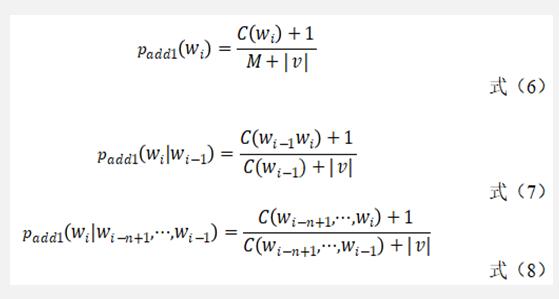
如此一来,训练语料中未出现的n-Gram的概率不再为 0,而是一个大于 0 的较小的概率值。Add-one 平滑算法确实解决了我们的问题,但显然它也并不完美。由于训练语料中未出现n-Gram数量太多,平滑后,所有未出现的n-Gram占据了整个概率分布中的一个很大的比例。因此,在NLP中,Add-one给训练语料中没有出现过的 n-Gram 分配了太多的概率空间。
由Add-one衍生出来的另外一种算法就是 Add-k。既然我们认为加1有点过了,不然选择一个小于1的正数 k。此时,add-one概率模型就变成了式(9)。通常,add-k算法的效果会比Add-one好,因k 必须人为给定,而这个值到底该取多少却有较大不确定性。
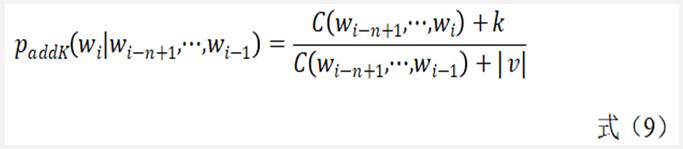
插值和回退的思想其实非常相像。设想对于一个trigram的模型,我们要统计语料库中三元组出现的次数,结果发现它没出现过,则计数为0。在回退策略中,将会试着用低阶低元组来进行替代,这很明显与实际的情况不相符。在使用插值算法时,我们把不同阶别的n-Gram模型通过线形加权统合后再来使用。


























 备案:
备案: