





Apache Kafka被设计成能够高效地处理大量实时数据,其特点是快速的、可扩展的、分布式的,分区的和可复制的。Kafka是用Scala语言编写的,虽然置身于Java阵营,但其并不遵循JMS规范。
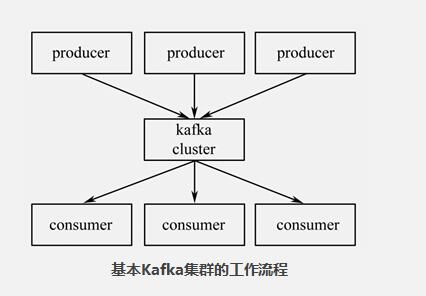
lTopics(话题):消息的分类名。
lProducers(消息发布者):能够发布消息到Topics的进程。
lConsumers(消息接收者):可以从Topics接收消息的进程。
lBroker(代理):组成Kafka集群的单个节点。
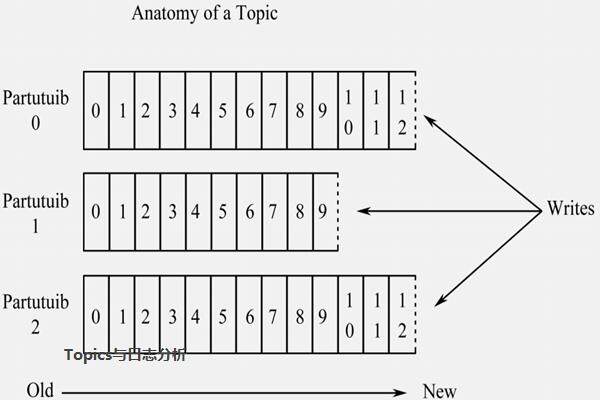
1、Topics
Topics是消息的分类名(或Feed的名称)。Kafka集群或Broker为每一个Topic都会维护一个分区日志。每一个分区日志是有序的消息序列,消息是连续追加到分区日志上,并且这些消息是不可更改的。
2、日志区分
一个Topic可以有多个分区,这些分区可以作为并行处理的单元,从而使Kafka有能力高效地处理大量数据。
3、Producers
Producers是向它们选择的主题发布数据。生产者可以选择分配某个主题到哪个分区上。这可以通过使用循环的方式或通过任何其他的语义分函数来实现。
4、Consumers
Kafka提供一种单独的消费者抽象,此抽象具有两种模式的特征消费组:Queuing 和Publish-Subscribe。
5、Apache Kafka的安装及使用
因为Kafka是处理网络上请求,所以,应该为其创建一个专用的用户,这将便于对Kafka相关服务的管理,减少对服务器上其他服务的影响。

























 备案:
备案: