





Hive介绍:
1、Hive工作原理
Hive本质上是一个SQL解析引擎,它将SQL语句转译成MapReduce作业并在Hadoop上执行。Hive执行过程如下,其工作原理如图。
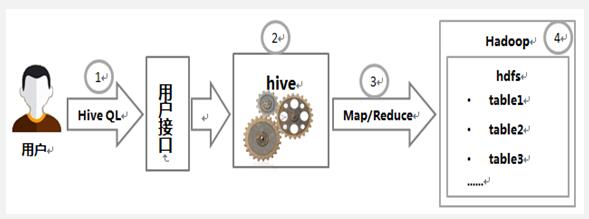
(1)用户通过用户接口连接Hive,发布Hive QL。
(2)Hive解析查询并制定查询计划。
(3)Hive将查询转换成MapReduce作业。
(4)Hive在Hadoop上执行MapReduce作业。
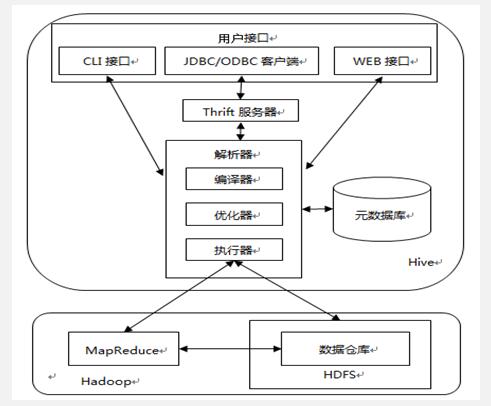
2.体现架构
Hive的体系架构如图所示,按功能主要分5大模块:用户接口、Thrift服务器、解析器、MetaStore元数据和Hadoop集群。
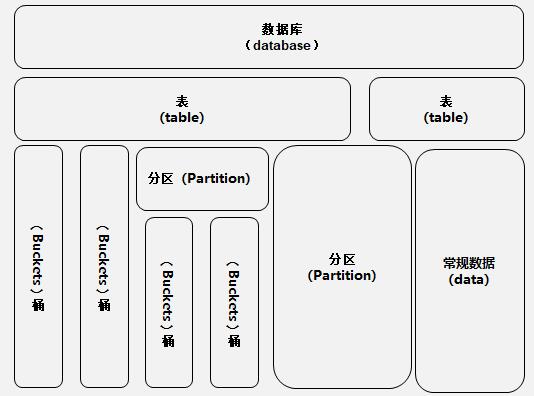
3.数据模型
Hive包含以下四种数据模型:内部表(Managed Table)、外部表(External Table)、分区(Partition)和桶(Bucket)。Hive中的数据存储如下图所示。
(1)内部表(Managed Table)。
每个Hive内部表在HDFS中都有对应目录用来存储表的数据。
内部表的创建过程和数据加载过程可以分别独立完成,也可以在同一个语句中完成。
删除内部表时,表中的数据和元数据会被同时删除。
(2)Hive外部表(External Table)
Hive外部表和内部表在元数据组织上是一样的,但在实际数据存储上有较大差异。
外部表数据不存储在自己表所属目录中,存储在LOCATION指定的HDFS路径中。
外部表仅有一个过程,创建表和数据加载过程同时进行和完成。
删除外部表仅仅是删除外部表对应的元数据,外部表所指向的数据不会被删除。
创建外部表使用EXTERNAL关键字。
(3)分区(Partition)
分区是表的部分列的集合。
一般为频繁使用的数据建立分区,在查找分区中数据时不用扫描全表,有利于提高查找效率。
Hive每个表有一个相应的目录存储数据,表中的的每一个分区对应表目录下的一个子目录,每个分区中的数据存储在对应子目录下的文件中。例如,表member(假定包含分区字段gender)在HDFS的路径为/user/hive/warehouse/member,分区gender=F对应的HDFS路径为/user/hive/warehouse/ member/gender=F,分区gender=M对应的HDFS路径为/user/hive/warehouse/member/gender=M,当导入数据到分区gender=F,则数据存储在/user/hive/warehouse/member/gender=F/000000_0文件中,当导入数据到分区gender=M,则数据存储在/user/hive/warehouse/member/gender=M/000000_0文件中。
(4) 桶(Bucket)
桶是将表的列通过Hash算法进一步分解成不同的文件存储。
对指定列计算hash值,根据hash值切分数据,目的是为了并行。
每一个桶对应一个文件(注意和分区的区别)。分区是粗粒度的划分,桶是细粒度的划分,这样可以让查询发生在小范围的数据上,提高查询效率,适合进行表连接查询,适合用于采样分析。比如,要将member表的id列分散至32个桶中,首先对id列的值进行Hash值计算,其中对应Hash值是0的数据存储在/hive/warehouse/member/000000_0文件中,对应Hash值是1的数据存储在/hive/warehouse/ member/000001_0文件中,依次类推。

























 备案:
备案: