





1.层次聚类算法
层次聚类算法的指导思想是对给定待聚类数据集合进行层次化分解。此算法又称为数据类算法,此算法根据一定的链接规则将数据以层次架构分裂或聚合,最终形成聚类结果。
从算法的选择上看,层次聚类分为自顶而下的分裂聚类和自下而上的聚合聚类。
分裂聚类初始将所有待聚类项看成同一类,然后找出其中与该类中其他项最不相似的类分裂出去形成两类。如此反复执行,直到所有项自成一类。
聚合聚类初始将所有待聚类项都视为独立的一类,通过连接规则,包括单连接、全连接、类间平均连接,以及采用欧氏距离作为相似度计算的算法,将相似度最高的两个类合并成一个类。如此反复执行,直到所有项并入同一个类。
典型代表算法,BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies,利用层次方法的平衡迭代规约和聚类)。
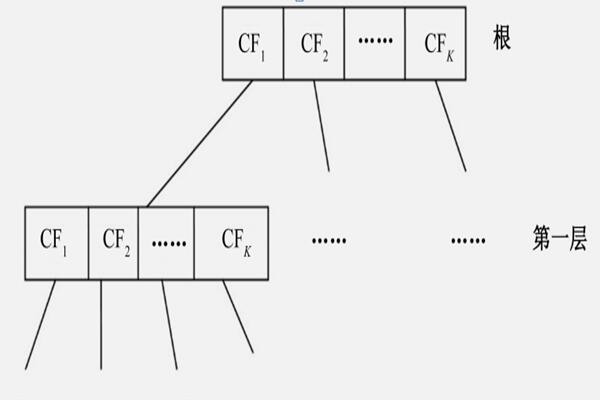
2.划分聚类算法
划分法属于硬聚类,指导思想是将给定的数据集初始分裂为K个簇,每个簇至少包含一条数据记录,然后通过反复迭代至每个簇不再改变即得出聚类结果。

K-Means算法也称作K-平均值算法或者K均值算法,是一种得到广泛使用的聚类分析算法。
K-Means算法是解决聚类问题的一种经典算法,简单快速,对于处理大数据集,该算法是相对可伸缩的和高效的

3.基于密度的聚类算法
基于密度聚类的经典算法DBSCAN(Density-Based Spatial Clustering of Application with Noise,具有噪声的基于密度的空间聚类应用)是一种基于高密度连接区域的密度聚类算法。
DBSCAN的基本算法流程如下:从任意对象P 开始根据阈值和参数通过广度优先搜索提取从P 密度可达的所有对象,得到一个聚类。若P 是核心对象,则可以一次标记相应对象为当前类并以此为基础进行扩展。得到一个完整的聚类后,再选择一个新的对象重复上述过程。若P 是边界对象,则将其标记为噪声并舍弃
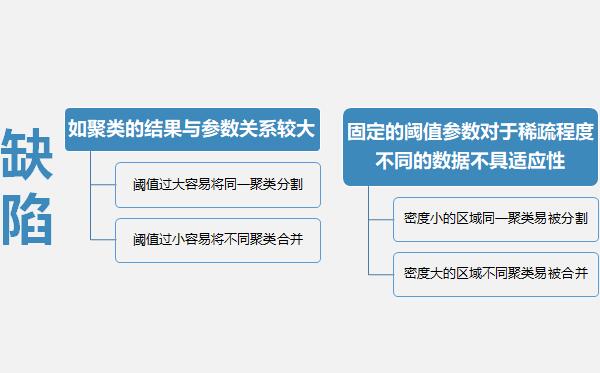
4.基于网格的聚类算法
基于网格的聚类算法是采用一个多分辨率的网格数据结构,即将空间量化为有限数目的单元,这些单元形成了网格结构,所有的聚类操作都在网格上进行。

5.基于模型的聚类算法
基于模型的聚类算法是为每一个聚类假定了一个模型,寻找数据对给定模型的最佳拟合。


























 备案:
备案: