





以网站文件下载为例,假定一组记录文件下载时间长度的原始数据集如表1-1所示。直接计算网站文件平均下载时长,计算结果约为23000秒,约6小时,与实际情况严重不符,说明这一数据集受到了显著的噪声的影响而导致部分数据值出现严重偏差。为此,必须对原始数据集做异常值识别并尽可能剔除错误数据。
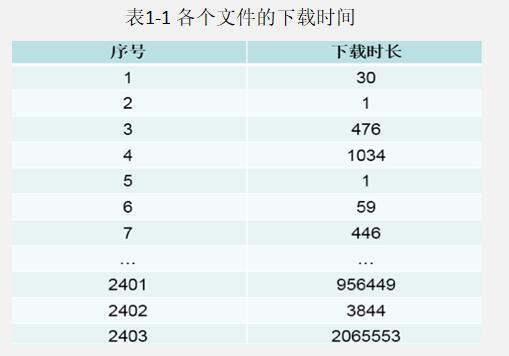
具体来说,可以基于数据的分布特征利用分箱法或聚类法来识别上例数据集中的噪声数据。对于表1中的数据,清洗数据时首先将数据集等分为2403个区间,找到数据的集中域[0, 3266]。然后,利用分箱法对取值在[0, 3266]之间的数据作进一步分析,对新数据组剔除离群值,得到清洗后的离群数据组。最后,统计计算清洗后的目标数据源的平均下载时长为192.93秒,约3.22分钟,符合网站文件下载的实际情况。从这个简单的例子可看出,基于数据的分布特征,数据清洗可以采用分箱法或聚类方法较为快捷地识别和剔除数据集中的噪声数据,从而获得良好的清洗效果。


























 备案:
备案: