





网络爬虫(又被称为网页蜘蛛、网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。网络爬虫还有另外一些不常使用的名字,如蚂蚁、自动索引、模拟程序或者蠕虫等。
网络爬虫的工作流程
网络爬虫的工作流程图如下图所示:
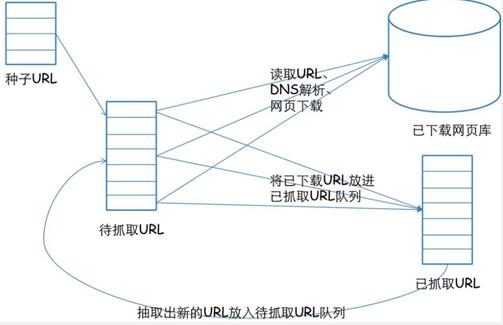
网络爬虫具体流程如下:
首先选取一部分种子URL
将这些URL输入待抓取URL队列
从待抓取URL队列中取出待抓取的URL,解析DNS,得到主机的IP地址,并将URL对应的网页下载下来,存储到已下载网页库中,再将这些URL放进已抓取URL队列
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入抓取URL队列

























 备案:
备案: