





R语言与数据挖掘应用实战实例:
背景:河流中海藻的集中爆发不仅会对河流的生态环境造成破坏,还会影响河流的水质;
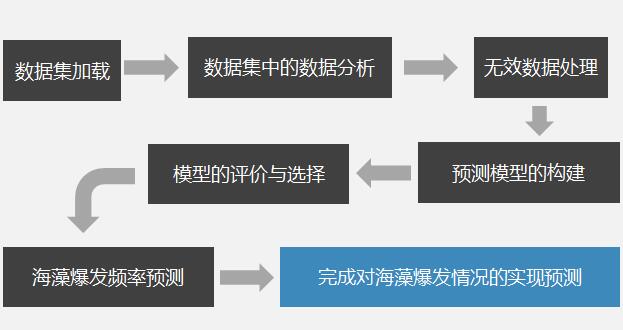
需求:基于以往的观测数据,对河流中海藻的爆发情况进行预测并采取必要防范措施以提高河流的水质量;
方法:以海藻样本数据为数据集,通过数据挖掘的方式分析影响海藻爆发的主要因素,并通过构建预测模型,对海藻的爆发情况进行事先预测。
部分代码:
线性回归和回归树模型的预测
> lm.predictions.a1 <- predict(final.lm, clean.algae) #计算线性回归模型的预测值
> rt.predictions.a1 <- predict(rt.a1, algae) #计算回归树模型的预测值
> mae.a1.lm <- mean(abs(lm.predictions.a1 - algae[, "a1"])) #计算预测值的平均误差
> mae.a1.rt <- mean(abs(rt.predictions.a1 - algae[, "a1"])) #计算预测值的平均误差
> mae.a1.lm #显示线性回归模型预测值的平均误差
[1] 13.10681
> mae.a1.rt #显示回归树模型预测值的平均误差
[1] 8.480619
回归树的MAE值为8.48
线性回归模型的MAE值 13.11
回归树模型的预测值的平均误差要优于线性回归模型预测值的平均误差

























 备案:
备案: