




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

正向学习神经元结构和计算方式
正向学习神经元结构和计算方式:其中为输入,x1,x2,x3为输入,b为偏置(一个常量),可以偏置将其视作一个权重为1的输入,为输入的加权和,为非线性的激活函数,用于将线性关系转换为非线性关系。
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-12-17 11:01:46
发布时间:2021-12-17 11:01:46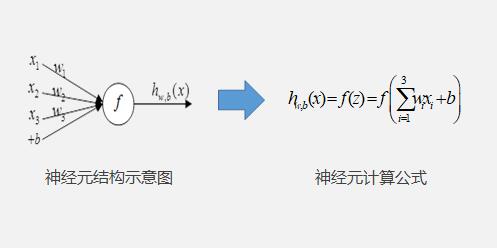
bp神经网络的优点和缺点
bp神经网络的优点和缺点:背景:1986年,适用于多层感知器(MLP)的反向传播(BP)算法被提出。BP网络实质:使用BP算法进行训练的多层前馈神经网络。缺陷:BP算法在1991年被指出存在“梯度消失”问题。
作者:云创智学 来源:云创智学
发布时间:2021-12-17 10:56:39感知机的优点和缺点
感知机的优点和缺点:特点:不同于M-P模型,感知器模型可以从样例中学习,并采用梯度下降法自动更新参数。缺陷:感知机只能解决线性可分问题,无法解决“异或”这种线性不可分问题。
作者:云创智学 来源:云创智学
发布时间:2021-12-17 10:55:06
机器学习特征选择的三种方法
机器学习特征选择概念:根据所特征选择是在原有的特征基础上筛选出重要的特征,以达到降低特征维度的目的。数据特征维度可能成千上万,这会造成维度灾难,过多的特征可能会造成计算缓慢,就需要找出冗余特征、贡献度低的特征,把这些特征剔除掉。机器学习特征选择的三种方法:1、Filter过滤法特征重要度排序,相关系数等,主要方法:卡方、方差、相关系数等。2、Wrapper包装法搜索优化、特征组合比较,如RFE算法。3、Embedded嵌入法学习模型的过程中,挑选出那些对模型训练有重要性的特征。特征和模型是分不开的,选择的特征不同训练的模型也是不同的。
作者:云创智学 来源:云创智学
发布时间:2021-12-17 10:50:13数据预处理与可视化分析
数据预处理与可视化分析:数据预处理可以分为数据清洗、数据变换等。数据清洗是对缺失值、异常值等处理,可采用插值方法,例如用平均值、中位数、众数、近邻数、回归方法进行补全或直接删除记录等。数据变换是对数据进行函数变换、规范化处理。数据的可视化分析能让数据变得通俗易懂和直接表达所传递的信息。在数据特征预处理后进行可视化分析,可以有效的帮助我们了解数据集的分布规律,对数据理解的越充分,越容易找到更好的特征,进行后续的机器学习建模。如统计分布:直方图、饼图、散点图、树等。
作者:云创智学 来源:云创智学
发布时间:2021-12-16 10:26:28
数据集的划分方法
数据集的划分方法:机器学习需要大量的数据样本、这些样本即为数据集、针对特定领域解决某个问题,就需要特定领域的数据(自建,公开数据集、伪数据集)。划分方法:训练集、开发集和测试集。具体方法:留出法,交叉验证法。根据经验,数据集的划分在小的数据集上采用70/30或者60/20/20法则。但是数据集很大比如有100万的时候,98/1/1会更加合理。一般来讲要让验证和测试能反映真实的使用场景。
作者:云创智学 来源:云创智学
发布时间:2021-12-16 10:23:33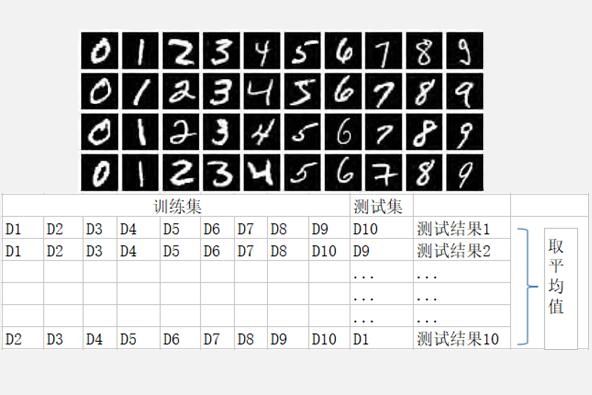
人工智能机器学习的基本流程
人工智能机器学习的基本流程:1、收集数据集日志,公开数据集、自建数据集。2、数据预处理数据类型、格式等。3、输入分析可视化分析数据的分布规律、可视化显示,更直观的看出数据分布和特征的异常。4、特征工程挖掘代表性的特征5、模型预测新数据算法学习、模型保存(网络结构、参数)。5、测试与参数调优模型验证、评估、优化参数。6、训练算法模型实际数据按照数据预处理的格式整理为格式化数据、利用算法模型进行实际工作环境中执行预测任务。
作者:云创智学 来源:云创智学
发布时间:2021-12-16 10:21:05人工智能机器学习的分类是什么,有那四种
人工智能机器学习的分类是什么:机器学习可划分为:监督学习、无监督学习、半监督学习,增强学习等。1、监督学习:人工标注样本集,包括样本的属性特征和类别标签两部分,同时给计算机学习,学习属性特征和类别标签内在的关系。(分类和回归);2、无监督学习:事先没有人工标注的样本、不知道原始结果是什么样子、给定的数据没有标签。最常用的任务是聚类、自动的将数据集分成不同的簇;3、半监督学习:同时利用了人工标记的样本数据和未标记的样本数据,半监督学习的目的是利用现有的数据学习训练出更好的模型,也就是可以自动的利用未标注的样本数据来提高学习性能;4、增强学习:它关注的是智能体如何在环境中采取一系列的行为,从而获得最大积累回报。通过增强学习,一个智能体知道在什么状态下应采取什么行为,其中从环境状态到动作映射的学习称之为策略。
作者:云创智学 来源:云创智学
发布时间:2021-12-16 10:17:47机器学习的定义是什么?
机器学习的定义是什么:主要通过从大量的数据中研究计算方法、利用经验来改善系统性能的一门学科,机器学习用到了统计学的知识、基于已有数据设计算法训练产生一定的模型,当有新的数据来临时,利用模型给出判断。从数据中学习规律来帮助人们进行预测或判断。将标注样本给计算机学习的过程称为训练,计算机会根据设计的算法从标注样本中学习参数,并最终学习一个能识别水果的模型。比如紫色、小圆,一串串的是葡萄。
作者:云创智学 来源:云创智学
发布时间:2021-12-16 10:15:30
非确定性推理的基本问题
非确定性推理的基本问题:非确定性推理,指在推理过程中,由于各种偶然性误差、干扰以及证据的不确定性等因素,导致所获得的结果或结论本身具有未知可否的不确定性。在人类思维活动中,不确定性是绝对的,其表现形式多种多样,主要表现为随机性、模糊性、不完全性、不一致性等。
作者:云创智学 来源:云创智学
发布时间:2021-12-15 11:38:01
 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信