




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

智能搜索的定义和概念
智能搜索的定义和概念:科学发展观要求建立人与自然和谐的社会,经济全球化、信息网络化、智能社会化成为当前发展的特征。探索人类智慧的道路,从思维科学走向社会智能科学,是时代的要求,体现了人文与科技的交融。在人工智能领域,所需求解的问题大多都具备结构不良或非结构化性质。这类问题通常并不存在“一马平川”式的求解方案。人们发现,很多问题的求解,其实可以通过试探性的搜索来获得。求解问题的第一步,就是把问题描述清楚,也就是目标的表示,它涉及到一种知识表示策略——状态空间表示法。第二步就是搜索策略。这里的“搜索”是指,智能系统尝试性地找到目标解的动作序列。搜索问题可分解为两个关键的子问题:(1)搜索什么;(2)在哪里搜索。前者是指搜索的解,即目标为何。后者是指搜索空间。搜索空间就是由一系列状态构成。那什么是状态呢?下面我们来讨论这个基础问题。
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-12-13 10:57:01
发布时间:2021-12-13 10:57:01脚本的特点是什么意思
脚本的特点是什么意思:由于脚本是一种框架结构,所以在具体应用前,我们需要根据环境对脚本中槽值进行赋值,这个过程成为脚本预先准备。在一个脚本中,场次描述了在一个特定的环境下将要发生的一系列、因果关系的事件,因此它能帮助预见未被直接观察到的事实,也可以对一组观测事实进行解释。由于脚本结构的特殊性,脚本与框架理论相比脚本要呆板得多,知识表示范围也很窄。但是对于一些特定领域,尤其是表达预先构思好的特定知识,脚本表示非常有效。
作者:云创智学 来源:云创智学
发布时间:2021-12-13 10:54:31人工智能脚本的结构是什么意思?
脚本是框架的一种特殊形式,它用一组槽描述某些事件发生的序列,就像一出剧中每个场次出现的顺序一样,故将这种表示方法称为脚本。不同的是,脚本所表达的不是一种完全通用的结构,它的各个槽和侧面已有固定的意义。在一个脚本中应包含以下内容:1)开场条件:描述事件发生的前提条件。2)角色:所描述事件中可能出现的人物的槽。3)道具:是一些用来描述事件中可能出现的有关物体的槽。4)场景:描述发生事件的真实顺序。一个事件可有多个场景组成,而每个场景又可以是其他的脚本。5)结局:在脚本中描述事件出现后所产生的结果,事件发生以后必须满足的条件。例如:以一家“餐厅”脚本为例来说明各个脚本各个部分的组成。1)进入条件:顾客饿了,需要进餐。顾客有足够的钱。2)角色:顾客、服务员、厨师、老板。3)道具:食品、桌子、菜单、钱。4)场景分别如下:场景1:进入餐厅顾客走进餐厅顾客注视桌子确定往哪儿走朝确定的桌子走在桌子旁坐下场景2:点菜服务员给顾客菜单顾客点菜顾客把菜单还给服务员顾客等待服务员送菜场景3:等待服务员告诉厨师顾客所点的菜厨师做菜顾客等待场景4:上菜进餐厨师把食品交给服务员服务员走向顾客服务员把食品交给顾客顾客吃食品场景5:离开服务拿来账单顾客付费给服务员顾客离开餐厅5)结局:顾客吃了饭,不饿了顾客花了钱老板赚了钱餐厅的食品少了服务员的业绩增加一单
作者:云创智学 来源:云创智学
发布时间:2021-12-13 10:50:19框架表示法的特点是什么
框架表示法的特点是什么:框架表示法的数据结构和问题求解过程与人类的思维和问题求解过程相似。框架结构表达能力强,层次结构丰富,提供了有效的组织知识的手段,只要对其中某些细节作进一步描述,就可以将其扩充为另外一些框架。框架表示法可以利用过去获得的知识对未来的情况进行预测,而实际上这种预测非常接近人的知识规律,因此可以通过框架来认识某一类事物,也可以通过一些实例来修正框架对某些事物的不完整描述(填充空的框架,修改默认值)。但是框架表示法与语义网络表示法存在着相似的问题,没有明确的推理机制保证问题求解的可行性和推理过程的严密性;由于许多实际情况与原型存在较大的差异,可能适应性不够强;框架表示法系统中各个子框架的数据结构如果不一致会影响整个系统的清晰性,造成推理的困难。总之,框架表示法基于认知科学理论来考察问题,应用人类的框架式知识模式去组织人类对真实事物的基本理解。因此,框架方法能捕获领域专家的思考方法,应用专家使用的专门技术充分表达对象和对象之间的关系,并实现概念和术语的简明定义。框架表示法是表示专业领域知识的理想方法。
作者:云创智学 来源:云创智学
发布时间:2021-12-13 10:48:00框架的构成包括以下四点组成
框架的构成包括以下四点组成:1、名字框架具有唯一的名字,它提供一个标志,可为任何常量。2、描述描述是框架的主体,由任意有限数目的槽组成。这些槽是数据和过程的组合模块,用于描述对象的性质(属性)或连接不同的其它框架。每个槽包含槽的名字和槽的值。一个框架中的每个槽具有唯一的名字,它局限于框架。因而不同的框架可以包含相同的槽名。每个槽有一个值侧面(存放属性值),它可具有一个或多个值,也可以是默认值。默认值是在缺乏更具体的知识时被假定的一个值。有些情况,根据对象的类型可知它必须具有某种特征,但不知道该特征的具体值,又不能设默认值。3、约束约束是每个槽可包含一组有关约束条件,如约束槽值的类型、数量等。这些约束可用若干侧面表示。一种侧面表示槽值的最少和最多个数;一种侧面描述槽值的类型和取值范围;例如一个人的年龄必须是整型数字。另一种侧面是附加过程:如果加入过程(if—added)、如果删除过程(if—deleted)、如果需要过程(if—needed),它们描述对象的行为特征,用于控制槽值的存储和检索。4、关系关系表达框架对象之间的知识关联,包括:等级关系、语义相似关系、语义相关关系等静态关联,还有框架之间的互操作等动态关联。每个框架可以有一个或多个父辈结点,通过父—子链表达等级关系。框架中槽的值也可以是连接其它框架的链值。因此,框架可以通过槽的值相互关联,还可以使用规则相互动态连接。当一个系统中的各个不同框架共享同一个槽时,这个槽可以把从不同角度收集来的信息相互协调起来。一个框架的基本结构由框架名、关系、槽、槽值及槽的约束条件与附加过程所组成。框架的一般描述形式如下:《框架名》《关系》《槽名1》《值1》《约束1》《过程l》《槽名2》《值2》《约束2》《过程2》……《槽名n》《值n》《约束n》《过程n》。例如:一个描述“大学教师”的框架:框架名——大学教师类属——职业:<教师>槽名——学位:(学士,硕士,博士)缺省:硕士槽名——专业:<学科专业>槽名——职称:(助教,讲师,副教授,教授)缺省:讲师槽名——外语:侧面名——语种:(英,法,日,俄)默认值:英侧面名——水平:(优,良,中,差)默认值:良
作者:云创智学 来源:云创智学
发布时间:2021-12-10 10:25:24知识图谱在搜索中的典型应用
知识图谱在搜索中的典型应用:1)查询理解搜索引擎借助知识图谱来识别查询中涉及到的实体(概念)及其属性等,并根据实体的重要性展现相应的知识卡片。搜索引擎并非展现实体的全部属性,而是根据当前输入的查询自动选择最相关的属性及属性值来显示。此外,搜索引擎仅当知识卡片所涉及的知识的正确性很高(通常超过95%,甚至达到99%)时,才会展现。当要展现的实体被选中之后,利用相关实体挖掘来推荐其他用户可能感兴趣的实体供进一步浏览。2)问题回答除了展现与查询相关的知识卡片,知识图谱对于搜索所带来的另一个革新是:直接返回答案,而不仅仅是排序的文档列表。要实现自动问答系统,搜索引擎不仅要理解查询中涉及到的实体及其属性,更需要理解查询所对应的语义信息。搜索引擎通过高效的图搜索,在知识图谱中查找连接这些实体及属性的子图并转换为相应的图查询。这些翻译过的图查询被进一步提交给图数据库进行回答返回相应的答案。
作者:云创智学 来源:云创智学
发布时间:2021-12-10 10:21:42知识图谱的表示方法是
知识图谱的表示方法是:以深度学习为代表的以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。1、代表模型1)、距离模型:距离模型提出了知识库中实体以及关系的结构化表示方法SE,其基本思想是:首先将实体用向量进行表示,然后通过关系矩阵将实体投影到与实体关系对的向量空间中,最后通过计算投影向量之间的距离来判断实体间已存在的关系的置信度。2)、单层神经网络模型:针对上述提到的距离模型中的缺陷,提出了采用单层神经网络的非线性模型SLM,模型为知识库中每个三元组(h,r,t)定义了一个评价函数。单层神经网络模型的非线性操作虽然能够进一步刻画实体在关系下的语义相关性,但在计算开销上却大大增加。3)、双线性模型:双线性模型又叫隐变量模型LFM,主要是通过基于实体间关系的双线性变换来刻画实体在关系下的语义相关性。模型不仅形式简单、易于计算,而且还能够有效刻画实体间的协同性。4)、神经张量模型在不同的维度下,将实体联系起来,表示实体间复杂的语义联系。神经张量模型在构建实体的向量表示时,是将该实体中的所有单词的向量取平均值,这样一方面可以重复使用单词向量构建实体,另一方面将有利于增强低维向量的稠密程度以及实体与关系的语义计算。5)、矩阵分解模型通过矩阵分解的方式可得到低维的向量表示,故不少研究者提出可采用该方式进行知识表示学习,知识库中的三元组集合被表示为一个三阶张量,如果该三元组存在,张量中对应位置的元素被置1,否则置为0。6)、翻译模型将知识库中实体之间的关系看成是从实体间的某种平移,并用向量表示。该模型的参数较少,计算的复杂度显著降低。与此同时,翻译模型在大规模稀疏知识库上也同样具有较好的性能和可扩展性。2、复杂关系模型知识库中的实体关系类型也可分为1-to-1、1-to-N、N-to-1、N-to-N4种类型,而复杂关系主要指的是1-to-N、N-to-1、N-to-N的3种关系类型。1)、TransH模型TransH模型尝试通过不同的形式表示不同关系中的实体结构,对于同一个实体而言,它在不同的关系下也扮演着不同的角色。TransH使不同的实体在不同的关系下拥有了不同的表示形式,但由于实体向量被投影到了关系的语义空间中,故它们具有相同的维度2)、TransR模型由于实体、关系是不同的对象,不同的关系所关注的实体的属性也不尽相同,将它们映射到同一个语义空间,在一定程度上就限制了模型的表达能力。模型首先将知识库中的每个三元组(h,r,t)的头实体与尾实体向关系空间中投影,然后希望满足给定的约束关系,最后计算损失函数。3)、TransD模型之前的TransR模型使它们被同一个投影矩阵进行映射,在一定程度上就限制了模型的表达能力。除此之外,将实体映射到关系空间体现的是从实体到关系的语义联系,而TransR模型中提出的投影矩阵仅考虑了不同的关系类型,而忽视了实体与关系之间的交互。因此,TransD模型分别定义了头实体与尾实体在关系空间上的投影矩阵。4)、TransG模型TransG模型认为一种关系可能会对应多种语义,而每一种语义都可以用一个高斯分布表示。TransG模型考虑到了关系r的不同语义,使用高斯混合模型来描述知识库中每个三元组(h,r,t)头实体与尾实体之间的关系,具有较高的实体区分。
作者:云创智学 来源:云创智学
发布时间:2021-12-10 10:20:19知识图谱构建技术的关键点是
知识图谱构建技术的关键点是:1)知识提取知识抽取主要是面向开放的链接数据,通常典型的输入是自然语言文本或者多媒体内容文档(图像或者视频)等。然后通过自动化或者半自动化的技术抽取出可用的知识单元,知识单元主要包括实体(概念的外延)、关系以及属性3个知识要素,并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。实体抽取:基于百科或垂直站点提取、基于规则与词典的实体提取方法、基于统计机器学习的实体抽取方法、面向开放域的实体抽取方法。2)语义类抽取:并列相似度计算、上下位关系提取、语义类生成。3)属性和属性值抽取属性提取的任务是为每个本体语义类构造属性列表(如城市的属性包括面积、人口、所在国家、地理位置等),而属性值提取则为一个语义类的实体附加属性值。4)关系抽取关系抽取的目标是解决实体语义链接的问题。关系的基本信息包括参数类型、满足此关系的元组模式等。
作者:云创智学 来源:云创智学
发布时间:2021-12-10 10:13:33知识图谱的架构
知识图谱的架构:1)知识图谱的逻辑结构知识图谱在逻辑上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,模式层构建在数据层之上,是知识图谱的核心,通常采用本体库来管理知识图谱的模式层。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。2)知识图谱的体系架构
作者:云创智学 来源:云创智学
发布时间:2021-12-10 10:11:58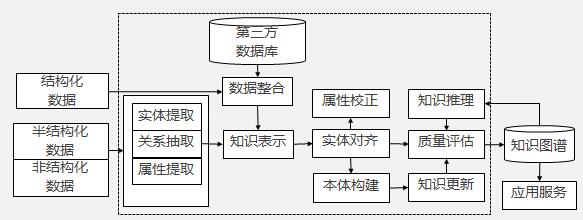
人工智能知识图谱概念和定义
人工智能知识图谱概念和定义:辛格博士在介绍知识图谱时提到的:“Theworldisnotmadeofstrings,butismadeofthings.””,知识图谱旨在描述真实世界中存在的各种实体或概念。其中,每个实体或概念用一个全局唯一确定的ID来标识,称为它们的标识符(identifier)。每个属性-值对(attribute-valuepair,又称AVP)用来刻画实体的内在特性,而关系用来连接两个实体,刻画它们之间的关联。知识图谱亦可看作是一张巨大的图,图中的节点表示实体或概念,而图中的边则由属性或关系构成。①实体:实体指的是具有可区别性且独立存在的某种事物。世间万物即为实体,如某一种动物、某一个人、某一种植物、某一种商品。②语义类(概念):主要指集合、类别、对象类型、事物的种类,如同人物、地理等。③内容:内容通常作为实体和语义类的名字、描述、解释等,可以由文本、图像、音视频等来表达。④属性(值):指一个实体指向它的属性值。不同的属性类型对应不同类型属性的边。属性值主要指对象指定属性的值。⑤关系:关系形式化为一个函数,它把K个点映射到一个布尔值。在知识图谱上,关系则是一个把K个图节点(实体、语义类、属性值)映射到布尔值的函数。三元组的基本形式主要包括(实体1—关系—实体2)和(实体—属性—属性值)等。每个实体(概念的外延)可用一个全局唯一确定的ID来标识,每个属性—属性值对AVP可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。换句话说,知识图谱是由一条条知识组成,每条知识表示为一个主语—谓语—宾语(SPO)三元组。主语主题可以是国际化资源标识符internationalizedresourceidentifiers(IRI)或空白节点(blanknode)。谓语属性通常是国际化资源标识符。宾语客体是国际化资源标识符、空白节点或常量。清华大学是一个实体,北京大学是一个实体,北京大学—院系—信息与工程科学部是一个(实体—关系—实体)的三元组样例。北京大学是一个实体,教工数是一种属性,20916是属性值。北京大学—教工数—20916构成一个(实体—属性—属性值)的三元组样例。
作者:云创智学 来源:云创智学
发布时间:2021-12-09 11:19:32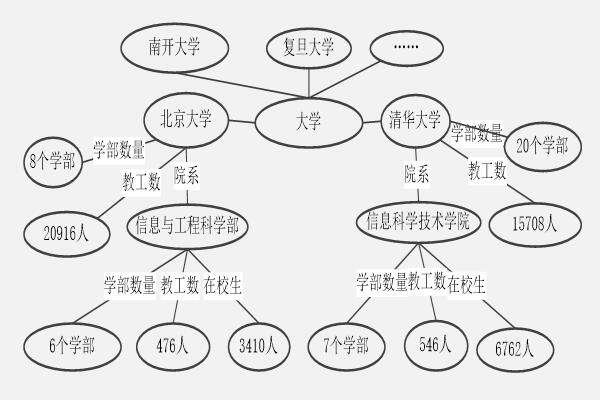

 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信