




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

环境大数据的概念
环境大数据的概念:1.环境数据的时空特性环境传感器数据的一个重要特点是除了信息本身所包含的环境物理量的测量值之外,其信息本身的时间和空间特征,也就是其分布信息也是非常关键的。大多数情况下,缺乏时空分布信息的环境数据是局部的,不完整的,其使用价值也相当有限。在时间维度上,环境数据可分为历史数据和实时数据,而各种预报系统则可以产生预报数据。2.多层次的数据采集国家环保部和各省级环保部门-传统环境数据监测大量布建低成本的空气质量环境监测设备3.多维度的环境数据整合1)气象气候数据最为常用的环境数据是气象数据。主要的气象数据包括天气现象、温度、气压、相对湿度、风力风向、降雨量、紫外线辐射强度以及气象预警事件等2)大气质量数据通过特征因子检测仪器及PM2.5监测设备监测污染因子:PM2.5、PM10、NO2、SO2、O3等空气中的主要污染物、H2S、NH3、NO2、SO2,以及有机溶剂气体,可燃气体等污染因子;空气中的花粉浓度、孢子浓度、大气背景的辐射强度在很多场合也是重要的环境监测对象因子。3)水体水质数据监视和测定水体中污染物的种类、各类污染物的浓度及变化趋势,包括未被污染和已受污染的天然水(江、河、湖、海和地下水)及各种各样的工业排水等。一类是反映水质状况的综合指标,如温度、色度、浊度、pH、电导率、悬浮物、溶解氧、化学需氧量和生化需氧量等;另一类是一些有毒物质,如酚、氰、砷、铅、铬、镉、汞和有机农药等。4)土壤质量数据通过对影响土壤环境质量因素的代表值的测定,确定环境质量(污染程度)及其变化趋势。监测因子包括pH、湿度、氮磷含量等。5)自然灾害数据台风、地震、洪水、龙卷风、泥石流、雷击等自然灾害的发生时间、地点、影响范围等。6)污染排放历史污染物及其他有害物质排放数据:用水量、用电量、化石燃料的用量。定量地衡量地区的工业化和城市化的水平
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-12-03 11:23:13
发布时间:2021-12-03 11:23:13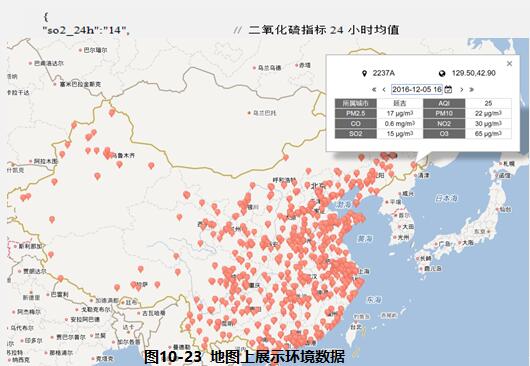
环境大数据的意义
环境大数据的意义:1、促进政府生态环境综合决策科学化、监管精准化、公共服务便民化2、有助于企业加快产业转型,发现新的商机,拓宽更广阔的市场3、给公众生活带来更多便利,提升生活质量,吸引公众关注和重视
作者:云创智学 来源:云创智学
发布时间:2021-12-03 11:13:31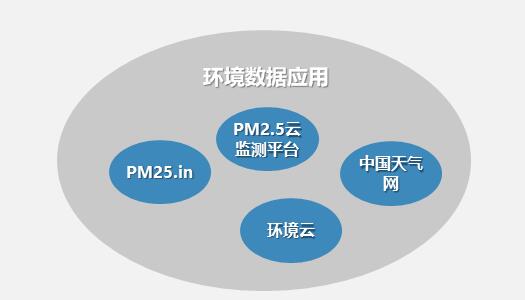
大数据挖掘技术在智能交通中的应用
大数据挖掘技术在智能交通中的应用:通过对交通数据进行宏观或微观的分析、统计和推理,分析不同属性因子之间存在的显性和隐形关系,利用现有的数据推断和预判未知的数据。数据挖掘是将人们对于交通信息的处理从最基本的查找、删改提高到了预测、预判。城市交通规划、交通管理、事件信息管理等都可以广泛使用数据挖掘。
作者:云创智学 来源:云创智学
发布时间:2021-12-03 11:10:41交通大数据应用技术有什么意义
交通大数据应用技术有什么意义:智慧交通整体框架:分析预测管理层:硬件传感器,采集交通状况和交通数据软件应用层:数据清洗、转换、聚合,支撑分析预警与交通规划辅助决策等物理感知层:数据挖掘算法,实现交通规划,道路实时路况分析、智能诱导等功能积极意义:第一,大数据提供环境监测方式。第二,大数据拥有信息集成优势和信息组合效率。第三,大数据的智能性可以合理配置公共交通资源。第四,提高交通安全水平。
作者:云创智学 来源:云创智学
发布时间:2021-12-02 12:01:06地震处理从复杂到简单-从“审慎的决策”到“快速的决策”
地震处理从复杂到简单-从“审慎的决策”到“快速的决策”:传统地震台网处理和决策都非常慎重,通过收集和分析数据来验证这种假设;如果有一些数据有问题,就影响原有假设,决策与行动是审慎的。小数据的地震速报可以较快地进行自动速报,但是处理复杂,要多中心审慎决策,特别是终报更需要审慎决策。原因是小数据依靠模型解算方程,由于空间数据间隔太大,往往初值确定度准确,大量计算可能仍然得不到可高的结果,必然影响快速决策。密集地震台网的大数据,不再受限于传统的方式,在密集的大数据中可以简单而准确地得到地震发生在哪里、多大,无须一而再地检查和复核,足以做出快速决定,地震预警的警报可以在数秒发出,地震烈度速报可以在几分钟就发出。快速决策无疑对于大地震的减轻灾害和挽救生命无疑具有重要的意义。
作者:云创智学 来源:云创智学
发布时间:2021-12-02 11:57:33大数据对地震有什么意义
大数据对地震有什么意义:美国地质调查局(USGS)启动了8个新的研究项目,目标是重新评估发生在所有主要板块边界和板块内部环境的地震等级、发生频率和震级分布,以及最大震级,以改进地震预警(测)模型,并使美国的灾害评估建立在更为强大的全球数据及其分析基础之上。高新技术和信息技术的发展,一直推动地震观测技术的进步。在移动互联网和物联网时代,微机电传感器(MEMS)技术和互联网智能技术使地震观测设备也遵循大数据产生的规律,即从精密到简单,从笨重到智能、从昂贵到低廉、从量少到量大。这完全是适应了地震预警和烈度速报应用需求,催生了密集地震观测网,也将地震行业带进了大数据时代。
作者:云创智学 来源:云创智学
发布时间:2021-12-02 11:55:46信用评分算法
信用评分算法:GBDT(GradientBoostingDecisionTree)又叫MART(MultipleAdditiveRegressionTree),该模型不像决策树模型那样仅由一棵决策树构成,而是由多棵决策树构成,通常都是上百棵树,而且每棵树规模都较小(即树的深度会比较浅)。模型预测的时候,对于输入的一个样本实例,首先会赋予一个初值,然后会遍历每一棵决策树,每棵树都会对预测值进行调整修正,最后得到预测的结果。F(x)=F_0+β_1T_1(x)+β_2T_2(x)+⋯+β_mT_m(x)其中,F_0为设置的初值,T_i是一棵棵的决策树(弱的分类器)。GBDT作为一种boosting算法,自然包含了boosting的思想,即将一系列弱分类器组合起来构成一个强分类器。它不要求每个分类器都学到太多的东西,只要求每个分类器都学一点点知识,然后将这些学到的知识累加起来构成一个强大的模型。
作者:云创智学 来源:云创智学
发布时间:2021-12-02 11:51:31机器学习在大数据金融中的作用
机器学习在大数据金融中的作用:在企业数据的应用的场景下,人们最常用的主要是监督学习和无监督学习的模型,在金融行业中一个天然而又典型的应用就是风险控制中对借款人进行信用评估。因此互联网金融企业依托互联网获取用户的网上消费行为数据、通讯数据、信用卡数据、第三方征信数据等丰富而全面的数据,可以借助机器学习的手段搭建互联网金融企业的大数据风控系统。除了在放贷前的信用审核外,互联网金融企业还可以借助机器学习完成传统金融企业无法做到的放贷过程中对借款人还贷能力进行实时监控,以及时对后续可能无法还贷的人进行事前的干预,从而减少因坏账而带来的损失。目前互联网金融企业以及第三方征信公司在信用评估这方面比较常用的架构是规则引擎加信用评分卡。
作者:云创智学 来源:云创智学
发布时间:2021-12-02 11:49:56用户标签是什么意思
用户标签体系从技术层面看,用户画像的过程比较乏味。但如何设计用户画像的标签体系却是一个看起来最简单、却最难以把握精髓的环节。什么是标签体系?简单说就是你把用户分到多少个类里面去。当然,每个用户是可以分到多个类上的。这些类都是什么,彼此之间有何联系,就构成了标签体系。标签体系的设计有两个常见要求,一是便于检索,二是效果显著。在不同的场景下,对这两点的要求重点是不同的。一般来说,设计一个标签体系以下三种思路。1.结构化标签体系结构化标签体系看起来整洁,又比较好解释,在面向品牌广告主交流时比较好用。性别、年龄这类人口属性标签,是最典型的结构化体系。2.半结构化标签体系在用于效果广告时,标签设计的灵活性大大提高了。标签体系是不是规整,就不那么重要了,只要有效果就行。在这种思路下,用户标签往往是在行业上呈现出一定的并列体系,而各行业内的标签设计则以“逮住老鼠就是好猫”为最高指导原则,切不可拘泥于形式。3.非结构化标签体系非结构化,就是各个标签就事论事,各自反应各自的用户兴趣,彼此之间并无层级关系,也很难组织成规整的树状结构。非结构化标签的典型例子,是搜索广告里用的关键词。还有Facebook用的用户兴趣词,意思也一样。半结构化标签操作上已经很困难了,非结构化的关键词为什么在市场上能够盛行呢?这主要是因为搜索广告的市场地位太重要了,围绕它的关键词选择和优化,已经形成了一套成熟的方法论。
作者:云创智学 来源:云创智学
发布时间:2021-12-01 16:57:11用户画像构建流程的三个主要步骤
用户画像构建流程:基础数据收集:网络行为数据、服务内行为数据、用户内容偏好数据、用户交易数据行为建模:文本挖掘、自然语言处理、机器学习、预测算法、聚类算法构建画像:基本属性、购买能力、行为特征、兴趣爱好、心理特征、社交网络1、数据收集与分析构建用户画像是为了将用户信息还原,构建一个用户数据模型。因此这些数据是基于真实的用户数据。用户数据可以大致分为网络行为数据、服务内行为数据、用户内容偏好数据、用户交易数据这四类。网络行为数据:活跃人数、页面浏览量、访问时长、激活率、外部触点、社交数据等服务内行为数据:浏览路径、页面停留时间、访问深度、页面浏览次数等用户内容偏好数据:浏览/收藏内容、评论内容、互动内容、生活形态偏好、品牌偏好等用户交易数据(交易类服务):贡献率、客单价、连带率、回头率、流失率等当然,收集到的数据不会是100%准确的,都具有不确定性,这就需要在后面的阶段中建模来再判断,比如某用户在性别一栏填的男,但通过其行为偏好可判断其性别为“女”的概率为80%。2、数据建模该阶段是对上阶段收集到数据的处理,进行行为建模,以抽象出用户的标签,这个阶段注重的应是大概率事件,通过数学算法模型尽可能地排除用户的偶然行为。这时也要用到机器学习,对用户的行为、偏好进行猜测,好比一个y=kx+b的算法,X代表已知信息,Y是用户偏好,通过不断的精确k和b来精确Y。在这个阶段,需要通过定性与定量相结合的研究方法来建立很多模型来为每个用户打上标签以及对应标签的权重。定性化研究方法就是确定事物的性质,是描述性的;定量化研究方法就是确定对象数量特征、数量关系和数量变化,是可量化的。3、构建用户画像的三个主要步骤1)把用户的基本属性(年龄、性别、地域)、购买能力、行为特征、兴趣爱好、心理特征、社交网络大致地标签化。2)当一切数据标签化并赋予权重后,即可根据构建用户画像的目的来搭建用户画像基本模型了。3)关于“标签化”,一般采用多级标签、多级分类。4、数据可视化分析如图所示,这是把用户画像真正利用起来的一步,在此步骤中一般是针对群体的分析,比如可以根据用户价值来细分出核心用户、评估某一群体的潜在价值空间,以做出针对性的运营。
作者:云创智学 来源:云创智学
发布时间:2021-12-01 16:53:52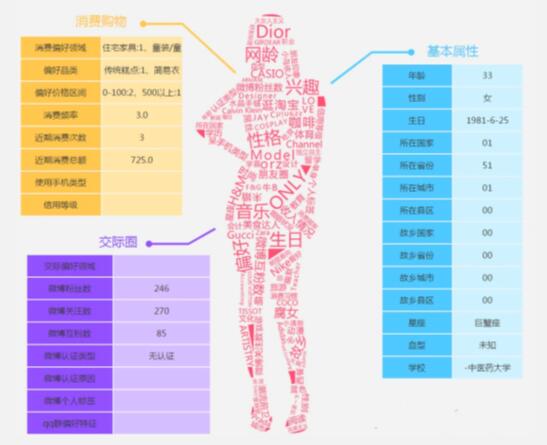

 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信