




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

用户画像概念描述
用户画像概念描述:人在网络世界中的行为集合代表了他在网络世界中的“性格”,这个集合就描述了他的网络个性和用户特征(UserProfile)。从数据拥有者,也就是企业角度来看,他们掌握了所有用户在网络世界中“某方面”的行为习惯,如用户浏览了哪些网页、搜索了哪些关键词、购买了哪些商品、留下了哪些评价等,企业都会收集汇总。如何将如此庞杂的数据转换为商业价值,成为现在企业越来越关注的问题。面对高质量、多维度的海量数据,如何建立精准的用户模型就显得尤为重要,用户画像的概念也就应运而生。用户画像,即用户信息的标签化,是企业通过收集、分析用户数据后,抽象出的一个虚拟用户,可以认为是真实用户的虚拟代表。用户画像的核心工作就是为用户匹配相符的标签,通常一个标签被认为是人为规定的高度精练的特征标识。1、用户画像从多维度对用户特征进行构造和刻画,包括用户的社会属性、生活习惯、消费行为等,进而可以揭示用户的性格特征。有了用户画像,企业就能真正了解了用户的所需所想,尽可能做到以用户为中心,为用户提供舒适快捷的服务。2、用户画像技术通过对用户的分析,让企业对用户的精准定位成为了可能。在这个基础上,依靠现代信息技术手段建立个性化的顾客沟通服务体系,将产品或营销信息推送到特定的用户群里中,既节省营销成本,又能起到最大化的营销效果。
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-12-01 14:50:45
发布时间:2021-12-01 14:50:45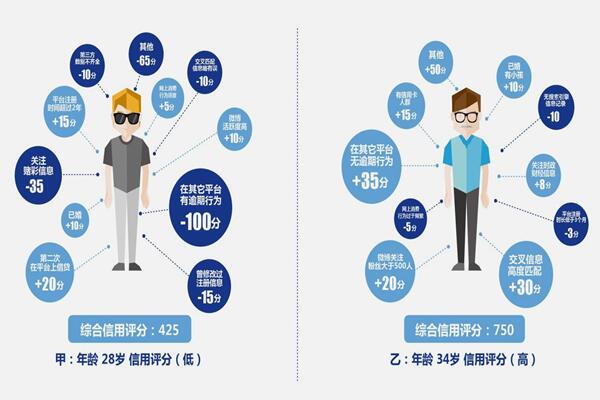
历史信息检索 数据抓取与整合的3种数据采集方式
历史信息检索数据抓取与整合的3种数据采集方式:1、手动录入提供内容输入的界面,由历史学家或爱好者手动录入历史事件2、半自动采集通过自然语言处理、机器学习和人工标注相结合的方法自动抽取历史事件的关键要素。3、面向历史领域的非结构化互联网数据抓取收录用户推荐的重要历史网站和系统自动抓取的历史相关的网页。
作者:云创智学 来源:云创智学
发布时间:2021-12-01 14:48:06历史信息检索系统架构
历史信息检索系统架构:面向历史领域的智能信息检索引擎,从互联网上抓取重大历史事件的网站内容,经过数据汇聚和整合从而在数据库中建立专门的数据库。通过在数据库中检索与用户查询条件匹配的相关记录,然后将查询结果进行优化,并按照一定的排序方式将最终结果返回给用户。全文检索系统架构图如下所示。
作者:云创智学 来源:云创智学
发布时间:2021-12-01 14:45:22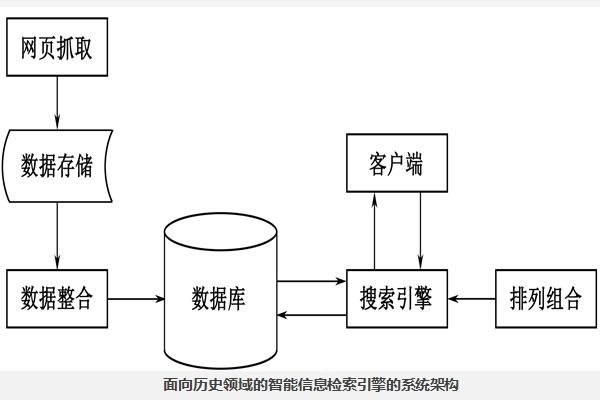
网页排序PageRank算法原理
网页排序PageRank算法原理:PageRank算法的核心思想是让页面之间通过超链接来进行“投票”:页面A上有一个指向页面H的超链接,就相当于页面A给页面H“投了一票”;一个网页被越多网页链接到,那么这个网页就越受大家信赖,此网页越重要,PageRank值越高;一个很重要、PageRank值很高的网页(如网页B)链接到了其他网页,那么这些网页的PageRank值也会因此提高。
作者:云创智学 来源:云创智学
发布时间:2021-11-30 11:48:12网页排序BM25算法原理详解
网页排序BM25算法原理详解:BM25算法是一种基于统计方法的排序算法,是二元独立模型的扩展,或者看作是TF-IDF算法的变形。此算法也是一种有效的相关性评分手段,被搜索引擎广泛使用。使用BM25算法来对查询到的网页进行评分,其关键代码如下:classBM25:def__init__(self,referance):self.referance=referanceself.k1=2self.k2=referance.wordCount/referance.fileCountself.b=0.75defgetRank(self,word,result):forfilenameinresult.keys():f=self.referance.invertedTable[word][filename]idf=math.log(self.referance.fileCount/len(self.referance.invertedTable[word]))result[filename]=(idf*f*(self.k1+1))/(f+self.k1*(1-self.b+self.b*self.k2))returnresult
作者:云创智学 来源:云创智学
发布时间:2021-11-30 11:46:51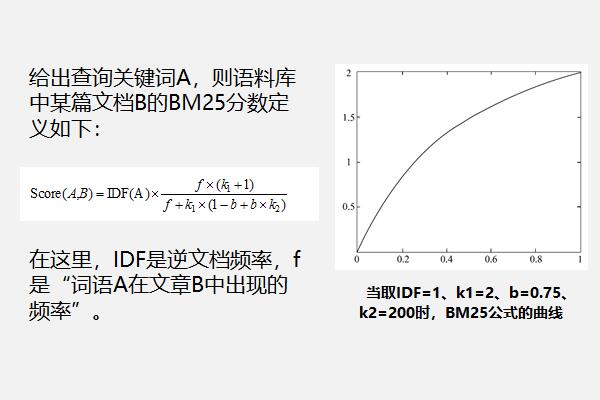
网页排序TD-IDF算法定义
网页排序TD-IDF算法定义:TF-IDF是一种统计方法,不仅可以用于评估一个词语对于语料库中某一份文档的重要程度,还可以对搜索结果进行排序,使“重要的”和“贴合搜索关键词的”网页排在前面。基于TF-IDF的网页评分系统在搜索引擎中被广泛使用。
作者:云创智学 来源:云创智学
发布时间:2021-11-30 11:44:02网页排序算法可分为4种
网页排序算法可分为4种如下:1、基于访问量的排序算法;2、基于词频统计和词语位置加权的排序算法;3、基于链接分析的排序算法;4、基于智能化的排序算法。
作者:云创智学 来源:云创智学
发布时间:2021-11-30 11:42:13倒排索引实现原理
倒排索引实现原理:1、任务概述要求对文件建立倒排索引,使之能够被方便地查询。2、遍历读取文件所有的文件都存放在文件夹中,首先要把这些文件读取出来,才能进行后续处理。3、对单个文件进行处理包括文本分词、去除无关词语、词语归一化和建立单个文件的信息统计表。4、将单个文件信息和总体的倒排表进行合并转变“词语-出现次数”统计表为“词语-文件-出现次数”倒排表。5、查询处理通过Key查找到对应的Value即可。
作者:云创智学 来源:云创智学
发布时间:2021-11-30 11:39:54大数据处理之倒排索引原理
大数据处理之倒排索引原理:如果使用一个矩阵来描述词语和文档之间的关系,不难得出如下“矩阵”。其中,每一列代表一个文档,每一行代表一个词语,每一个单元格代表“此文档中出现此词语的次数”。一、词语和文档的关系:矩阵中的第一列说明“在文档1中,词语1出现了4次、词语2和词语3均出现了3次,并且文档1中不再有其他词语出现”。同理,矩阵中的第一行则说明“词语1在文档1中出现在4次,在文档4中出现1次,在其他文档中不出现”。其他行列同理。二、倒排索引的数据结构:倒排索引可以使用这样一个Map来实现:每一个词语都是Map中的一个键(Key),这个键对应的Value是一个集合,里面保存着包含这个词语的文档的编号。存储形式为:Map<Stringkey,Set<Struct<DocID>value>>。同理,如果要在倒排索引中加入更多信息,可以在Value中增加记录项目。三、倒排索引的建立实例:假设现在有两篇文档,每篇文档的内容如下:其建立实例的步骤如下:1.文章本分词2.去除无关词语3.词语归一化4.建立词语-文档矩阵5.建立到排索引四、倒排索引的更新策略:1、完全重建策略先进行“文档暂存”,待文档暂存区达到一定数量后,对所有文档重新建立索引。2、再合并策略新文档会立即被解析,解析结果会进行“索引暂存”,待索引暂存区达到一定数量后,再将新旧索引合并。3、原地更新策略新文档立刻被解析,解析结果立刻被加入旧索引中。4、混合策略其思想是混合地使用上述几种策略,取长补短,以达到最好的性能。
作者:云创智学 来源:云创智学
发布时间:2021-11-30 11:37:14
斯坦福NLTK分词工具介绍
斯坦福NLTK分词工具:有些文本的形成和变化过程与时间是紧密相关的,因此,如何将动态变化的文本中时间相关的模式与规律进行可视化展示,是文本可视化的重要内容。引入时间轴是一类主要方法,常见的技术以河流图居多。河流图按照其展示的内容可以划分为主题河流图、文本河流图及事件河流图等。
作者:云创智学 来源:云创智学
发布时间:2021-11-29 11:38:30

 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信