




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

边缘计算架构定义为
边缘计算架构定义为:1、实时计算系统2、轻量计算系统3、智能网关系统4、智能分布式系统
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-12-23 10:34:08
发布时间:2021-12-23 10:34:08边缘计算的特点有哪些
边缘计算的特点有哪些:1、连接性2、数据入口3、约束性4、分布性5、融合性
作者:云创智学 来源:云创智学
发布时间:2021-12-23 10:31:51分布式人工智能是什么意思
分布式人工智能是什么意思:分布式人工智能(DistributedArtificialIntelligence,DAI)将人工智能与分布式计算相结合,在通信、计算、控制的基础上打造深度信息物理融合系统(CyberPhysicalSystem,CPS),并通过移动边缘网络、多智能体协同、群智感知策略等技术实现分布式感知、计算与决策,以应对大型复杂系统的智能化体系构建。
作者:云创智学 来源:云创智学
发布时间:2021-12-23 10:19:57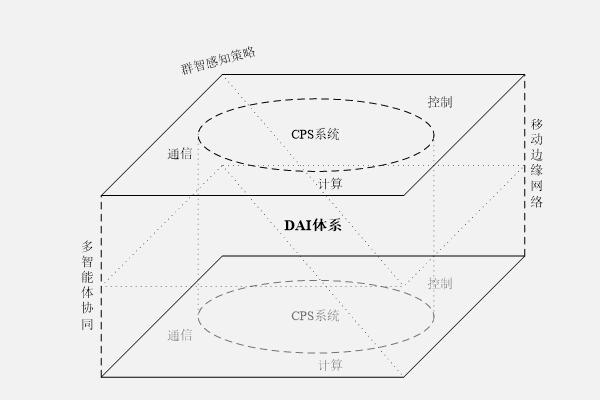
概率图模型有哪几种
概率图模型有哪几种:概率图结合了概率论与图论知识,节点和边表达概率相关关系的模型的总称,以建立一套通用自然语言智能推理理论。解决非确定性问题的传统思路就是利用概率论的思想,但是随着问题的复杂不断增加,传统的概率方法显得越来越力不从心。图模型的引入使人们可以将复杂问题得到适当的分解,变量表示为节点,变量与变量之间的关系表示为边,这样就使问题结构化。概率图理论就自然地分为三个部分,概率图模型表示理论、概率图模型推理理论和概率图模型学习理论。模型的表示。贝叶斯网络(有向无环图)和马尔科夫随机场(无向图)两类。在自然语言处理中最常用的就是各种基于马尔科夫的各种概率图模型。模型的学习。模型的学习是指将给定的概率模型表示为数学公式。模型的学习精度受以下三方面的影响:第一语料库样本集对总体的代表性;第二模型算法的理论基础及所针对的问题。不同模型因为原理不同,能够处理的语言问题也不同,比如朴素贝叶斯模型在处理文本分类方面精度很高;最大熵模型在处理中文词性标注问题上表现很好,条件随机场模型处理中文分词、语义组块等方面的精度很高;第三模型算法的复杂度。模型的预测。用模型学习阶段的得到的模型,把最大的后验概率作为预测的结果。
作者:云创智学 来源:云创智学
发布时间:2021-12-23 09:53:48语言模型的平滑方法
语言模型的平滑方法:Add-one是最简单、最直观的一种平滑算法。既然希望没有出现过的n-Gram的概率不再是0,那就不妨规定任何一个n-Gram在训练语料至少出现一次(即规定没有出现过的n-Gram在训练语料中出现了一次),对于unigram模型而言,Add-one模型可由式(6)计算得来,其中,M是训练语料中所有的n-Gram的数量,而v是所有的可能的不同的n-Gram的数量。同理,对于bi-gram模型而言,可得由式(7)得来;推而广之,对于n-Gram模型而言,可由式(8)计算而来。如此一来,训练语料中未出现的n-Gram的概率不再为0,而是一个大于0的较小的概率值。Add-one平滑算法确实解决了我们的问题,但显然它也并不完美。由于训练语料中未出现n-Gram数量太多,平滑后,所有未出现的n-Gram占据了整个概率分布中的一个很大的比例。因此,在NLP中,Add-one给训练语料中没有出现过的n-Gram分配了太多的概率空间。由Add-one衍生出来的另外一种算法就是Add-k。既然我们认为加1有点过了,不然选择一个小于1的正数k。此时,add-one概率模型就变成了式(9)。通常,add-k算法的效果会比Add-one好,因k必须人为给定,而这个值到底该取多少却有较大不确定性。插值和回退的思想其实非常相像。设想对于一个trigram的模型,我们要统计语料库中三元组出现的次数,结果发现它没出现过,则计数为0。在回退策略中,将会试着用低阶低元组来进行替代,这很明显与实际的情况不相符。在使用插值算法时,我们把不同阶别的n-Gram模型通过线形加权统合后再来使用。
作者:云创智学 来源:云创智学
发布时间:2021-12-23 09:47:51语料库是什么意思
云创智学:语料库是自然语言处理的基础资源,是自然语言模型训练的基础。语料库有多种类型,依据语料采集的原则和方式上,可以把语料库分成四类。异质语料库指没有特定的语料收集原则,广泛收集并原样存储各种语料;同质语料库只收集同一类内容的语料;系统语料库指按一定比例收集语料,使语料具有平衡性,能够代表语言事实;专用语料库指只收集某一特定领域或用途的语料。除此之外,按照语料的语种,语料库也可以分成单语、双语和多语。按照语料库是否标注,又可分为生语料库和熟语料库以下是我国10大知名语料库,中央研究院近代汉语标记语料库;中央研究院汉籍电子文献;国家现代汉语语料库;国家语委现代汉语语料库;树图数据库;语料库语言学在线;北京大学中国语言学研究中心,简称CCL语料库检索系统;北京大学《人民日报》标注语料库;北京语言大学的语料库;清华大学的汉语均衡语料库。
作者:云创智学 来源:云创智学
发布时间:2021-12-23 09:29:35句法理论与自动分析
句法理论与自动分析:依存语法(DependencyParsing,DP)往往是一种基于规则的专家系统,通过分析语言单位内成分之间的依存关系揭示其句法结构。直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系,往往最终生成的结果,是一棵句法分析树。句法分析可以解决传统词袋模型不考虑上下文的问题。仍然是上面的例子,其分析结果如下图9-1所示。从分析的结果中我们可以看到,句子的核心谓词为“强调”,而不是“增强”,主语是“李荣增”而不是“李荣”,宾语是“广州市应积极...”,“发改文主任”是李荣增的定语。有了上面的句法分析结果,我们就可以比较容易的看到,“强调者”是“李荣增”,而强调的内容是“广州市应积极...”。依存语法本质上研究词和词之间的依存关系。一个依存关系连接两个词,分别是核心词(head)和依存词(dependent)。目前主要采用研究主要集中在基于数据驱动的依存句法分析方法,即在训练实例集合上学习得到依存句法分析器,而不涉及依存语法理论的研究基于图的依存句法分析方法。基于图的方法将依存句法分析问题看成从完全有向图中寻找最大生成树的问题。一棵依存树的分值由构成依存树的几种子树的分值累加得到。根据依存树分值中包含的子树的复杂度,基于图的依存分析模型可以简单区分为一阶和高阶模型。基于图的方法通常采用基于动态规划的解码算法,也有一些学者采用柱搜索(beamsearch)来提高效率。学习特征权重时,通常采用在线训练算法,如平均感知器(averagedperceptron)。基于转移的依存句法分析方法。基于转移的方法将依存树的构成过程建模为一个动作序列,将依存分析问题转化为寻找最优动作序列的问题。早期,研究者们使用局部分类器(如支持向量机等)决定下一个动作。近年来,研究者们采用全局线性模型来决定下一个动作,一个依存树的分值由其对应的动作序列中每一个动作的分值累加得到。特征表示方面,基于转移的方法可以充分利用已形成的子树信息,从而形成丰富的特征,以指导模型决策下一个动作。模型通过贪心搜索或者柱搜索等解码算法找到近似最优的依存树。和基于图的方法类似,基于转移的方法通常也采用在线训练算法学习特征权重。多模型融合的依存句法分析方法。基于图和基于转移的方法从不同的角度解决问题,各有优势。基于图的模型进行全局搜索但只能利用有限的子树特征,而基于转移的模型搜索空间有限但可以充分利用已构成的子树信息构成丰富的特征。因此,研究者们使用不同的方法融合两种模型的优势,常见的方法有:stackedlearning;对多个模型的结果加权后重新解码(re-parsing);从训练语料中多次抽样训练多个模型(bagging),取得了较好的效果。
作者:云创智学 来源:云创智学
发布时间:2021-12-23 09:24:45自然语言处理原理词性标注
自然语言处理原理词性标注:词性标注(Part-of-speechTagging,POS)是基于机器学习的方法给句子中每个词一个词性类别的任务。这里的词性类别可能是名词、动词、形容词或其他。词性作为对词的一种泛化,在语言识别、句法分析、信息抽取等任务中有重要作用。下面的句子是一个词性标注的例子。其中,v代表动词、n代表名词、c代表连词、d代表副词、wp代表标点符号。哈尔滨工业大学LTP系统词性标记集中采用863词性标注集。如同分词一样,基于机器学习的方法依然是当前分词的最有效手段,本节简要概述以基于隐马尔可夫模型的分词算法。一个句子经过分词后是一组词序列,这是我们可以观察到的,其实在词序列的背后还有一个词性序列。比如,一个词序列“小赵是个勤奋的学生”,隐含还有一个词性序列“名词动词量词形容词名词标点”。因此,对于给定的词序列,对词性的标准过程就是求与词序列对应的具有最大概率的一个词性序列。
作者:云创智学 来源:云创智学
发布时间:2021-12-21 13:55:52自然语言处理原理汉语分词
自然语言处理原理汉语分词:中英文都存在分词的问题,英文每个单词之间以空格为分割符进行分割,所以处理起来相对方便。中文分词是将汉字序列切分成词序列。鉴于中文字之间没有分隔符,所以分词问题有较大的挑战。当前中文分词常用的方法有,基于字典的最长串匹配和基于统计机器学习算法。前者易于实现,可以解决85%的问题,但是歧义分词很难避免;而当前基于隐尔马科夫模型(HiddenMarkovModel,HMM)和条件随机场(ConditionalRandomField,CRF)等统计模型的解决方案已成为分词技术主流。分词算法主要包括基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法三种。当前基于统计方法进行分词,因为较高的性能,已经成为分词主流。基于统计的分词方法是在给定大量已标注的语料库的前提下,训练机器学习模型来实现对未知文本的切分。主要的统计模型有:N元文法模型(N-gram),隐马尔可夫模型(HiddenMarkovModel,HMM),最大熵模型(ME),条件随机场模型(ConditionalRandomFields,CRF)和循环神经网络(RecurrentNeuralNetwork,RNN)等
作者:云创智学 来源:云创智学
发布时间:2021-12-21 13:55:05计算机处理模型规则方法
计算机处理模型规则方法:在计算模型研究方面,有规则方法和统计方法两种。由于自然语言在本质上属于人类社会因交流需要而产生的符号系统,其规则和推理特征鲜明,因此早期自然语言处理的研究首要采用规则方法。1、人类语言毕竟不是形式语言,规则模式往往隐式存在语言当中,致使规则的制定并不容易。2、自然语言的复杂性使得规则很难既无冲突又能涵盖全部的语言现象,于是这种基于规则方法使得自然语言处理研究长时间停留在一种小范围可用的阶段。3、当我们想要得到一个好的自然语言模型,在设计反映语言现象的模型以及合适的特征设计方面,仍离不开自然语言处理研究人员对语言的深入理解及其智力的支持。
作者:云创智学 来源:云创智学
发布时间:2021-12-21 13:53:22
 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信