




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

数据清洗 重要变量选择方法
数据清洗重要变量选择方法:1、Boruta包>qsar.data<-read.csv(file=file.choose(),header=T)>colnames(qsar.data)>fs.data<-qsar.data[,-1];colnames(fs.data)>library(Boruta)#载入Boruta包,对重要变量进行选择>fs.data.extended<-Boruta(activity~.,data=fs.data,doTrace=2,maxRuns=100,light=TRUE,confidence=1.999)>print(fs.data.extended)#查看变量选择结果>table(fs.data.extended$finalDecision)>getConfirmedFormula(fs.data.extended)#查看接收的变量>getNonRejectedFormula(fs.data.extended)#查看通过变量选择被接收变量及可供选择的变量2、subselect包的genetic函数>qsar.data<-read.csv(file=file.choose(),header=T)>dim(qsar.data);colnames(qsar.data)>library(subselect)>qsar.dataHmat<-lmHmat(qsar.data[,c(3:23)],qsar.data[,2])>names(qsar.data[,2,drop=FALSE])>colnames(qsar.dataHmat)>genetic(qsar.dataHmat$mat,kmin=2,H=qsar.dataHmat$H,r=1,crit="CCR12")3、subselect包的anneal函数>qsar.data<-read.csv(file=file.choose(),header=T)>library(subselect)
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-12-29 17:28:44
发布时间:2021-12-29 17:28:44数据清洗,数据去重方法
数据清洗数据去重方法:数据重复检测函数包括unique、duplicated。unique对于一个向量管用,对于matrix、dataframe那些就不管用了。duplicated函数是一个可以用来解决向量或者数据框重复值的函数,它会返回一个TRUE和FALSE的向量,以标注该索引所对应的值是否是前面数据所重复的值。以数据data.set为例,说明解决办法。(1)建立是否重复索引>index<-duplicated(data.set$Ensembl)>index[1]FALSETRUEFALSETRUETRUETRUETRUETRUETRUEFALSE>data.set2<-data.set[!index,]#去掉重复行
作者:云创智学 来源:云创智学
发布时间:2021-12-29 17:26:45数据清洗缺失值处理方法有哪些
对于缺失数据通常有三种方法:方法1:当缺失数据较少时直接删除相应样本方法2:对缺失数据进行插补方法3:使用对缺失数据不敏感的分析方法,如决策树。【例7.1】mice包使用>library(mice)>imp=mice(sleep,seed=1234)>fit=with(imp,lm(Dream~Span+Gest))>pooled=pool(fit)>summary(pooled)
作者:云创智学 来源:云创智学
发布时间:2021-12-29 17:25:32
周期性分析方法概念
周期性分析方法概念:周期性分析是探索某个变量是否随着时间变化而呈现出某种周期变化趋势。时间尺度相对较长的周期性趋势有年度周期性趋势、季节周期性趋势,相对较短的有月度周期性趋势、周度周期性趋势,甚至更短的天、小时周期性趋势。例如,要对某单位用电量进行预测,可以先分析该用电单位日用电量的时序图,以此来直观地估计其用电量变化趋势。
作者:云创智学 来源:云创智学
发布时间:2021-12-29 17:21:40对比分析的四个步骤
对比分析的四个步骤:1、对比分析原理数据的趋势变化独立的看,其实很多情况下并不能说明问题,比如如果一个企业盈利增长10%,我们并无法判断这个企业的好坏,如果这个企业所处行业的其他企业普遍为负增长,则5%很多,如果行业其他企业增长平均为50%,则这是一个很差的数据。对比分析,就是给孤立的数据一个合理的参考系,否则孤立的数据毫无意义。2、常用对比分析方法①同比。同比(year-on-year)就是今年第n月与去年第n月比,即同期相比。同比发展速度主要是为了消除季节变动的影响,用以说明本期发展水平与去年同期发展水平对比而达到的相对发展速度。如,本期2月比去年2月,本期6月比去年6月等。其计算公式为:(本期数-同期数)/|同期数|×100%。②环比。年报的同比分析就是用报告期数据与上期或以往几个年报数据进行对比。它可以告诉投资者在过去一年或几年中,上市公司的业绩是增长还是滑坡。但是,年报的同比分析不能揭示公司最近6个月的业绩增长变动情况,而这一点对投资决策更富有指导意义。③定基比。定基比的算法是环比指数的乘积,比如你要求2012年8月的定基比,那么,你就要知道2012年1-8月份的环比指数,然后得出的乘积就是定基比,别忘了%。④三者之间关系。统计指标按其具体内容、实际作用和表现形式可以分为总量指标(同比)、相对指标(环比)和平均指标(定基比)。同比和环比,这两者所反映的虽然都是变化速度,但由于采用基期的不同,其反映的内涵是完全不同的;一般来说,环比可以与环比相比较,而不能拿同比与环比相比较;而对于同一个地方,考虑时间纵向上发展趋势的反映,则往往要把同比与环比放在一起进行对照。3、对比的参照物不同,得到的判断结论也就不同孩子考试考了95分,家长很高兴,因为知道满分是100分,有参照物。最近一次考试考了80分,家长会发火,因为过去的95分成了新参照物。后来一问,发现这次卷子出难了,孩子已经是班级第一了,就又转怒为喜,这里其他孩子就成了参照物。
作者:云创智学 来源:云创智学
发布时间:2021-12-28 11:16:53分布分析法举例
分布分析法举例:1、定量数据的分布分析方法1:直方图将数据取值的范围分成若干等距区间,考察数据落入每一区间的频数与频率,在每个区间上画一个矩形,它的宽度是组距,它的高度可以是频数,这种直方图可以估计总体的概率密度。在R语言中,使用hist()函数画出样本的直方图。方法2:核密度图与直方图相配套的是核密度图,其目的是用已知样本,估计其密度,执行下面代码得到图6.6。>set.seed(1234)>x<-rnorm(100,0,1)>hist(x,breaks=10,freq=FALSE,col="gray")>lines(density(x),col="red",lwd=2)方法2:茎叶图与直方图比较,茎叶图更能细致地看出数据分布结构。R语言中使用stem()函数绘制茎叶图,如:>stem(islands)Thedecimalpointis3digit(s)totherightofthe|0|000000000000000000000000000001111112223382|074|56|88|410|512|14|16|0在茎叶图中,纵轴为测定数据,横轴为数据频数,数据的十分位表示“茎”,作为纵轴的刻度;个位数作为“叶”,显示频数的个数,作用与直方图类似。3、定性数据的分布分析对于定性变量,常常根据分类变量来分组,可以采用饼图来描述定性变量的分布。饼图的每一个扇形部分代表每一类型的百分比或频数,根据定性变量的类型数目将饼形图分成几个部分,每一部分的大小与每一类型的频数成正比。
作者:云创智学 来源:云创智学
发布时间:2021-12-28 11:09:24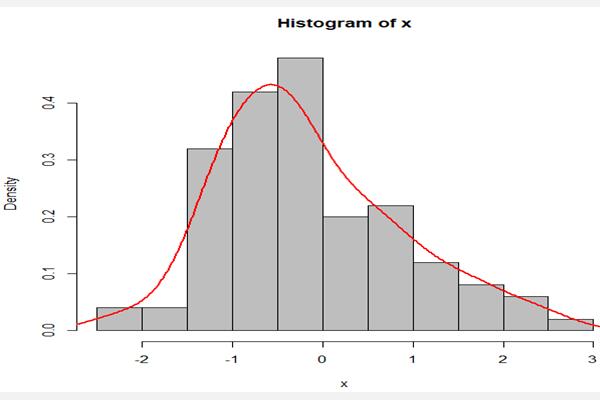
LOF方法检测异常值
LOF方法检测异常值:局部异常因子法(LOF法),是一种基于概率密度函数识别异常值的算法。LOF算法只对数值型数据有效。算法原理:将一个点的局部密度与其周围的点的密度相比较,若前者明显比后者小(LOF值大于1),则该点相对于周围的点来说就处于一个相对比较稀疏的区域,这就表明该点是一个异常值。R语言实现:使用DMwR包中的函数lofactor(),基本格式为:lofactor(data,k)其中,data为数值型数据集;k为用于计算局部异常因子的邻居数量。>library(DMwR)>out.scores<-lofactor(USArrests,k=10)#计算每个样本的LOF值>plot(density(out.scores))#绘制LOF值的概率密度图(如图6.5)>#LOF值排前6的数据作为异常值,提取其样本号>order(out.scores,decreasing=TRUE)[1:6][1]33911452034
作者:云创智学 来源:云创智学
发布时间:2021-12-28 11:04:35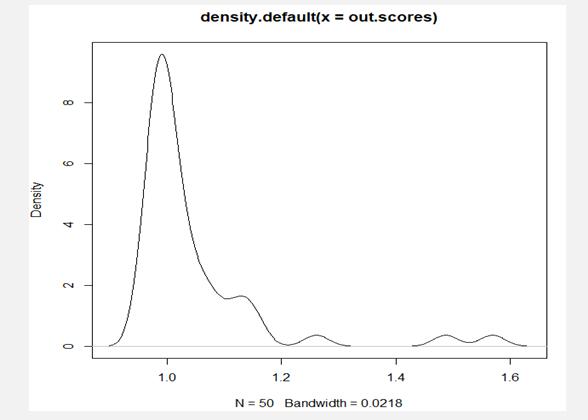
与缺失值相关的几个概念
与缺失值相关的几个概念:1、FLASE(假)FALSE表示逻辑假,是存在的真实值。计算时FALSE被当做0。2、NA(缺失值)NA表示数据集中的该数据遗失、不存在。在针对具有NA的数据集进行函数操作的时候,该NA参与运算,如。>x<-c(1,2,3,NA,4);mean(x)[1]NA如果想去除NA的影响,需要显式告知mean方法,如mean(x,na.rm=T)。3、NULLNULL表示未知的状态,它不会在计算之中。例如,x<-c(1,2,3,NULL,4),取mean(x),结果为3.5。4、NaNNaN:无意义的数,比如sqrt(-2),0/0
作者:云创智学 来源:云创智学
发布时间:2021-12-28 11:01:33ggplot2介绍和如何使用
ggplot2介绍和如何使用:1、特点ggplot2的核心理念是将绘图与数据分离,数据相关的绘图与数据无关的绘图分离。ggplot2是按图层作图。ggplot2保有命令式作图的调整函数,使其更具灵活性。ggplot2将常见的统计变换融入到了绘图中。2、画布ggplot(data=,mapping=)3、图层图层可以允许用户一步步的构建图形,方便单独对图层进行修改。图层用+表示,如:>p<-ggplot(data=,mapping=)>p<-p+绘图命令4、绘图命令几何绘图命令:geom_XXX(aes=,alpha=,position=),见几何对象。其中,alpha表示透明度,position表示位置。统计绘图命令:stat_XXX(),见映射。标度绘图命令:scale_XXX,见统计对象。其它修饰命令:标题、图例、统计对象、几何对象、标度和分面等。5、说明绘图命令不能独立使用,必须与画布配合使用。
作者:云创智学 来源:云创智学
发布时间:2021-12-28 10:59:24R语言字符串处理stringr包处理方法
R语言字符串处理stringr包处理方法:1、字符串拼接函数str_c:字符串拼接。str_join:字符串拼接,同str_c。str_trim:去掉字符串的空格和TAB(\t)str_pad:补充字符串的长度str_dup:复制字符串str_wrap:控制字符串输出格式str_sub:截取字符串str_sub<-截取字符串,并赋值,同str_sub2、字符串计算函数str_count:字符串计数str_length:字符串长度str_sort:字符串值排序str_order:字符串索引排序,规则同str_sort3、字符串匹配函数str_split:字符串分割str_split_fixed:字符串分割,同str_splitstr_subset:返回匹配的字符串word:从文本中提取单词str_detect:检查匹配字符串的字符str_match:从字符串中提取匹配组。str_match_all:从字符串中提取匹配组,同str_matchstr_replace:字符串替换str_replace_all:字符串替换,同str_replacestr_replace_na:把NA替换为NA字符串str_locate:找到匹配的字符串的位置。str_locate_all:找到匹配的字符串的位置,同str_locatestr_extract:从字符串中提取匹配字符str_extract_all:从字符串中提取匹配字符,同str_extract4、字符串变换函数str_conv:字符编码转换str_to_upper:字符串转成大写str_to_lower:字符串转成小写,规则同str_to_upperstr_to_title:字符串转成首字母大写,规则同str_to_upper
作者:云创智学 来源:云创智学
发布时间:2021-12-27 10:59:37
 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信