




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

SparkDataFrames的概念和用法
SparkDataFrames的概念和用法:SparkR的核心是SparkDataFrames,是一个基于Spark的分布式数据框架。在概念上和关系型数据库中的表类似,或者和R语言中的数据框类似。SparkDataFrame可以完成以下操作:(1)数据缓存控制:cache(),persist(),unpersist();(2)数据保存:saveAsTextFile(),saveAsObjectFile();(3)常用的数据转换操作:如map(),flatMap(),mapPartitions()等;(4)数据分组、聚合操作:如partitionBy(),groupByKey(),reduceByKey()等;(5)join操作:如join(),fullOuterJoin(),leftOuterJoin()等;(6)排序操作,如sortBy(),sortByKey(),top()等;(7)Zip操作,如zip(),zipWithIndex(),zipWithUniqueId();(8)重分区操作,如coalesce(),repartition()。
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2022-01-06 11:32:43
发布时间:2022-01-06 11:32:43SparkR下载安装配置教程
spark下载安装配置教程:此安装步骤是Spark跑在HadoopYarn架构上的安装方式,如果是跑在独立的Spark环境上,请参照SparkR官网(https://github.com/amplab-extras/SparkR-pkg)。1、安装依赖包:install.packages("rJava")yuminstalllibcurlyuminstalllibcurl-develinstall.packages("RCurl")install.packages("devtools")服务器需要安装maven服务(参照:http://blog.csdn.net/zdnlp/article/details/74575962、安装SparkR包library(devtools)install_github("amplab-extras/SparkR-pkg",subdir="pkg")USE_YARN=1SPARK_YARN_VERSION=2.4.0SPARK_HADOOP_VERSION=2.4.0USE_MAVEN=1./install-dev.sh3、Linux下加载R包install.packages('Cairo',dependencies=TRUE,repos='http://cran.rstudio.com/')在R或Rstudio中调用SparkR:library(SparkR)sc<-sparkR.init(master="local","RwordCount")lines<-textFile(sc,"hdfs://XXXIP):8020/test/log.txt")words<-flatMap(lines,function(line){strsplit(line,",")[[1]]})count(words)
作者:云创智学 来源:云创智学
发布时间:2022-01-06 11:31:05hadoo安装详细教程和配置
hadoo安装详细教程和配置:1、下载依赖包https://github.com/RevolutionAnalytics/RHadoop/wiki/Downloadsrmr-2.1.0rhdfs-1.0.5rhbase-1.1复制到/root/R目录~/R#pwd/root/R~/R#lsrhbase_1.1.tar.gzrhdfs_1.0.5.tar.gzrmr2_2.1.0.tar.gz2、安装rJava库,在配置好了JDK1.6的环境后,运行RCMDjavareconf命令,R的程序从系统变量中会读取Java配置。然后打开R程序,通过install.packages的方式安装rJava。3、安装依赖库在命令行执行:RCMDjavareconfR启动R程序install.packages("rJava")install.packages("reshape2")install.packages("Rcpp")install.packages("iterators")install.packages("itertools")install.packages("digest")install.packages("RJSONIO")install.packages("functional")4、安装rhdfs库,在环境变量中增加HADOOP_CMD和HADOOP_STREAMING两个变量:vi/etc/environmentHADOOP_CMD=/root/hadoop/hadoop-1.0.3/bin/HadoopHADOOP_STREAMING=/root/hadoop/hadoop-1.0.3/contrib/streaming/hadoop-streaming-1.0.3.jar5、安装rmr库RCMDINSTALLrmr2_2.1.0.tar.gz6、安装rhbase库安装完成HBase后,还需要安装Thrift,因为rhbase是通过Thrift调用HBase的。Thrift是需要本地编译的,官方没有提供二进制安装包,首先下载thrift-0.8.0。在Thrift解压目录输入./configure,会列Thrift在当前机器所支持的语言环境,如果只是为了rhbase,默认配置就可以了。7、安装rhbase。下载thriftwgethttp://archive.apache.org/dist/thrift/0.8.0/thrift-0.8.0.tar.gztarxvfthrift-0.8.0.tar.gzcdthrift-0.8.0/下载PHP支持类库(可选)sudoapt-getinstallphp-cli下载C++支持类库(可选)sudoapt-getinstalllibboost-devlibboost-test-devlibboost-program-options-devlibevent-devautomakelibtoolflexbisonpkg-configg++libssl-dev生成编译的配置参数./configure编译和安装makemakeinstall查看thrift版本thrift-versionThriftversion0.8.0启动HBase的ThriftServer/hbase-0.94.2/bin/hbase-daemon.shstartthriftjps安装rhbaseRCMDINSTALLrhbase_1.1.1.tar.gz8、查看安装的类库一般R的类库目录是/usr/lib/R/site-library或者/usr/local/lib/R/site-library,用户也可以使用whereisR的命令查询,自己计算机上R类库的安装位置。ls/disk1/system/usr/local/lib/R/site-library/digestfunctionaliteratorsitertoolsplyrRcppreshape2rhdfsrJavaRJSONIOrmr2stringr以上是hadoo安装详细教程和配置教程。
作者:云创智学 来源:云创智学
发布时间:2022-01-06 11:26:32Hadoop是什么?
Hadoop是什么:1、Hadoop家族的强大之处在于对大数据的处理,让原来的不可能(TB,PB数据量计算),成为了可能。所以,hadoop重点是海量数据分析。2、R语言的强大之处在于统计分析,在没有Hadoop之前,我们对于大数据的处理。可以看出,两种技术放在一起,刚好是取长补短。
作者:云创智学 来源:云创智学
发布时间:2022-01-06 11:19:47收视率是怎么统计的
收视率是怎么统计的:收视率,指在某个时段收看某个电视节目的目标观众人数占总目标人群的比重,以百分比表示。现在一般由第三方数据调研公司,通过电话,问卷调查,机顶盒或其他方式抽样调查来得到收视率。节目平均收视率指观众平均每分钟收看该节目的百分比,收视总人口指该节目播出时间内曾经观看的人数(不重复计算),所以有时会出现收视率较低,收视人口较高的状况,但排名仍以收视率为准通常都是1.8%、0.9%,意思就是全国100个人中就有几个人在看。作为"注意力经济"时代的重要量化指标,它是深入分析电视收视市场的科学基础,是节目制作、编排及调整的重要参考,是节目评估的主要指标,是制定与评估媒介计划、提高广告投放效益的有力工具。虽然收视率本身只是一个简单的数字,但是在看似简单的数字背后却是一系列科学的基础研究、抽样和建立固定样组、测量、统计和数据处理的复杂过程。
作者:云创智学 来源:云创智学
发布时间:2022-01-05 09:26:04ROC曲线的作用有哪些?
ROC曲线的作用有哪些:1、ROC曲线能很容易判断边界值的分类能力。2、选择最佳的诊断界限值。ROC曲线越靠近左上角,试验的准确性就越高。最靠近左上角的ROC曲线的点是错误最少的最好阈值,其假阳性和假阴性的总数最少。3、两种或两种以上不同诊断试验对疾病识别能力的比较。在对同一种疾病的两种或两种以上诊断方法进行比较时,可将各试验的ROC曲线绘制到同一坐标中,以直观地鉴别优劣,靠近左上角的ROC曲线所代表的受试者工作最准确。亦可通过分别计算各个试验的ROC曲线下的面积(AUC)进行比较,哪一种试验的AUC最大,则哪一种试验的诊断价值最佳。
作者:云创智学 来源:云创智学
发布时间:2022-01-05 09:23:06什么是ROC曲线
什么是ROC曲线:受试者工作特征曲线(receiveroperatingcharacteristiccurve,简称ROC曲线),又称为敏感曲线,得此名的原因在于曲线上各点反映着相同的敏感性,它们都是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已。ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感度=TP/(TP+FN))为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。传统的诊断试验评价方法有一个共同的特点,必须将试验结果分为两类,再进行统计分析。ROC曲线的评价方法与传统的评价方法不同,无须此限制,而是根据思维,允许有中间状态,可以把试验结果划分为多个有序分类,如正常、大致正常、可疑、大致异常和异常五个等级再进行统计分析。因此,ROC曲线评价方法适用的范围更为广泛。
作者:云创智学 来源:云创智学
发布时间:2022-01-05 09:21:27二分类混淆矩阵怎么看
二分类混淆矩阵怎么看:混淆矩阵是将每个观测数据实际的分类与预测类别进行比较。混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了观测数据的真实归属类别,每一行的数据总数表示该类别的观测数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目。这些指标通常对区分误分类错误类型有用。例如,在weather数据集中。假阳性将预测明天会下雨,但事实上并非如此。结果是,我可能会带伞,但没有用到。假阴性预测结果是明天没有雨,但实际下了,如果依据模型的预测,你不需要带雨伞,不幸的是遇到大雨,你被淋湿了。在这个例子中,假阴性比假阳性更重要。TP(真阳性)表示阳性样本经过正确分类之后被判为阳性。TN(真阴性)表示阴性样本经过正确分类之后被判为阴性。FP(假阳性)表示阴性样本经过错误分类之后被判为阳性。FN(假阴性)表示阳性样本经过错误分类之后被判为阴性。
作者:云创智学 来源:云创智学
发布时间:2022-01-05 09:19:30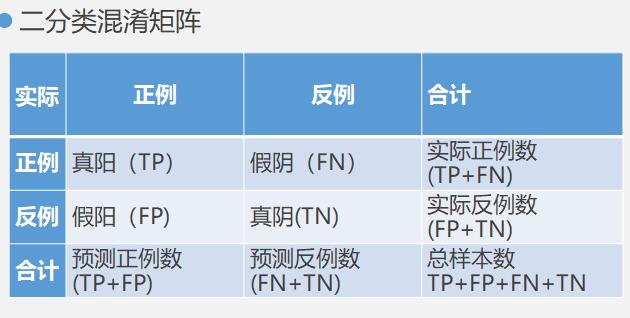
测试数据集的定义是什么
测试数据集的定义是什么:测试数据集是一个在建模阶段没有使用过的数据集。一旦根据验证数据集确定了“最好”的模型,那么在测试集上对模型的性能评估。然后,在任何新的数据集上估计模型预期的性能。Data标签的第四个选项是使用全集评估模型(联合训练、验证和测试数据集)。这中策略似乎只对玩具项目有用,而不能精确的评估模型的性能。在Data标签中,作为数据源的另一个选项是通过输入提供选择。当打分(Score)选为评价的类型时才使用。在这种情况下,弹出一个窗口允许直接输入数据。Data标签数据源的最后两个选项,一个是CSV文件,另一个是RDataset。它们允许数据从一个CSV文件加载到R中,作为模型评估数据集。模型性能评价是通过交叉验证完成的。事实上,R中一些算法就是执行交叉验证来评估,决策树算法使用的rpart()就是一个例子。交叉验证的概念很简单。给定一个数据集,随机分割10份,使用其中的9份来建模,用最后的那1份度量模型的性能,重复选择不同的9份构成训练集,余下的那1份用作测试,需要重复10次,10次测试的平均作为最后的模型性能度量。
作者:云创智学 来源:云创智学
发布时间:2022-01-05 09:17:19训练数据集是什么意思?
训练数据集:训练数据集是用于建模的,所以通常情况下,在训练数据集上模型执行得很好。但个结论并不能真的说明模型好,我们更希望知道模型对看不见的数据有怎样的表现。为了回答这个问题,需要把模型应用到数据上。这样做之后,将得到模型的总体错误率。简单的做法就是把观察数据按比例划分,对比模型结果和实际结果差异。使用验证数据集测试模型的性能,同时微调模型。因此,建立一个决策树之后,我们要在验证数据集再一次检查模型的性能。我们可能会改变一些用于构建决策树模型的参数调节选项。基于模型在验证数据集性能与旧模型对比,得到一个最终的模型性能的偏差估计。
作者:云创智学 来源:云创智学
发布时间:2022-01-04 11:21:17
 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信