




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

SPMGC算法的基本处理流程
SPMGC算法的基本处理流程:1、扫描时间序列数据库,获取满足约束条件且长度为1的序列模式L1,以序列模式L1作为初始种子集2、根据长度为i-1的种子集Li-1,通过连接与剪切运算生成长度为i并且满足约束条件的候选序列模式Ci,基于此扫描序列数据库,并计算每个候选序列模式Ci的支持数,从而产生长度为I的序列模式Li,将Li作为新种子集3、在此重复上一步,直至没有新的候选序列模式或新的序列模式产生SPBGC算法首先对约束条件按照优先级进行排序,然后依据约束条件产生候选序列。SPBGC算法说明了怎样使用约束条件来挖掘序贯模式,然而,由于应用领域的不同,具体的约束条件也不尽相同,同时产生频繁序列的过程也可采用其他序贯模式算法。
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-11-11 14:05:14
发布时间:2021-11-11 14:05:14时间序列预测方法有哪些
时间序列:对按时间顺序排列而成的观测值集合,进行数据的预测或预估。典型的算法:序贯模式挖掘SPMGC算法序贯模式挖掘算法SPMGC(SequentialPatternMiningBasedonGeneralConstrains)SPMGC算法可以有效地发现有价值的数据序列模式,提供给大数据专家们进行各类时间序列的相似性与预测研究。时间序列领域约束规则如下图SPMGC算法的基本处理流程:SPBGC算法首先对约束条件按照优先级进行排序,然后依据约束条件产生候选序列。SPBGC算法说明了怎样使用约束条件来挖掘序贯模式,然而,由于应用领域的不同,具体的约束条件也不尽相同,同时产生频繁序列的过程也可采用其他序贯模式算法。
作者:云创智学 来源:云创智学
发布时间:2021-11-11 14:01:41
预测与预测模型是什么意思?以及预测分类的方法
预测分析是一种统计或数据挖掘解决方案,包含可在结构化与非结构化数据中使用以确定未来结果的算法和技术,可为预测、优化、预报和模拟等许多其他相关用途而使用。时间序列预测是一种历史资料延伸预测,以时间序列所能反映的社会经济现象的发展过程和规律性,进行引申外推预测发展趋势的方法。时间序列预测及数据挖掘分类:预测方案分类:
作者:云创智学 来源:云创智学
发布时间:2021-11-11 13:53:37
数据挖掘关联规则 保险客户风险分析案例
数据挖掘关联规则保险客户风险分析案例:1.挖掘目标由过去大量的经验数据发现机动车辆事故率与驾驶者及所驾驶的车辆有着密切的关系,影响驾驶人员安全驾驶的主要因素有年龄、性别、驾龄、职业、婚姻状况、车辆车型、车辆用途、车龄等。因此,客户风险分析的挖掘目标就是上述各主要因素与客户风险之间的关系,等等。2.数据预处理数据准备与预处理是数据挖掘中的首要步骤,高质量的数据是获得高质量决策的先决条件。在实施数据挖掘之前,及时有效的数据预处理可以解决噪声问题和处理缺失的信息,将有助于提高数据挖掘的精度和性能。3.关联规则挖掘详细分析所得数据,可以为公司业务提供数据支撑,针对不同客户提供偏好服务,既能确保公司收益,又能给予用户更多的实惠。
作者:云创智学 来源:云创智学
发布时间:2021-11-10 13:50:57
关联规则之分类技术法原理
分类技术原理:分类技术或分类法(Classification)是一种根据输入样本集建立类别模型,并按照类别模型对未知样本类标号进行标记的方法。1.决策树决策树就是通过一系列规则对数据进行分类的过程。决策树分类算法通常分为两个步骤:构造决策树和修剪决策树。2.k-最近邻最临近分类基于类比学习,是一种基于实例的学习,它使用具体的训练实例进行预测,而不必维护源自数据的抽象(或模型)。它采用n维数值属性描述训练样本,每个样本代表n维空间的一个点,即所有的训练样本都存放在n维空间中。若给定一个未知样本,k-最近邻分类法搜索模式空间,计算该测试样本与训练集中其他样本的邻近度,找出最接近未知样本的k个训练样本,这k个训练样本就是未知样本的k个“近邻”。其中的最近邻分类是基于要求的或懒散的学习法,即它存放所有的训练样本,并且直到新的(未标记的)样本需要分类时才建立分类。其优点是可以生成任意形状的决策边界,能提供更加灵活的模型表示。
作者:云创智学 来源:云创智学
发布时间:2021-11-10 13:44:35
辛普森悖论产生的原因
辛普森悖论产生的原因:虽然关联规则挖掘可以发现项目之间的有趣关系,在某些情况下,隐藏的变量可能会导致观察到的一对变量之间的联系消失或逆转方向,这种现象就是所谓的辛普森悖论(Simpson’sParadox)。为了避免辛普森悖论的出现,就需要斟酌各个分组的权重,并以一定的系数去消除以分组数据基数差异所造成的影响。同时必须了解清楚情况,是否存在潜在因素,综合考虑。
作者:云创智学 来源:云创智学
发布时间:2021-11-10 13:31:21FP-Growth算法原理
FP-Growth算法原理频繁模式树增长算法(FrequentPatternTreeGrowth)采用分而治之的基本思想,将数据库中的频繁项集压缩到一棵频繁模式树中,同时保持项集之间的关联关系。然后将这棵压缩后的频繁模式树分成一些条件子树,每个条件子树对应一个频繁项,从而获得频繁项集,最后进行关联规则挖掘。
作者:云创智学 来源:云创智学
发布时间:2021-11-10 13:29:36
apriori算法原理
apriori算法原理:Apriori算法基于频繁项集性质的先验知识,使用由下至上逐层搜索的迭代方法,即从频繁1项集开始,采用频繁k项集搜索频繁k+1项集,直到不能找到包含更多项的频繁项集为止。Apriori算法由以下步骤组成,其中的核心步骤是连接步和剪枝步:
作者:云创智学 来源:云创智学
发布时间:2021-11-10 13:27:52
频繁项集 关联规则产生及其经典算法
频繁项集关联规则产生及其经典算法:格结构(LatticeStructure)常常被用来枚举所有可能的项集。1.Apriori算法Apriori算法基于频繁项集性质的先验知识,使用由下至上逐层搜索的迭代方法,即从频繁1项集开始,采用频繁k项集搜索频繁k+1项集,直到不能找到包含更多项的频繁项集为止。Apriori算法由以下步骤组成,其中的核心步骤是连接步和剪枝步:2.FP-Growth算法频繁模式树增长算法(FrequentPatternTreeGrowth)采用分而治之的基本思想,将数据库中的频繁项集压缩到一棵频繁模式树中,同时保持项集之间的关联关系。然后将这棵压缩后的频繁模式树分成一些条件子树,每个条件子树对应一个频繁项,从而获得频繁项集,最后进行关联规则挖掘。3.辛普森悖论虽然关联规则挖掘可以发现项目之间的有趣关系,在某些情况下,隐藏的变量可能会导致观察到的一对变量之间的联系消失或逆转方向,这种现象就是所谓的辛普森悖论(Simpson’sParadox)。为了避免辛普森悖论的出现,就需要斟酌各个分组的权重,并以一定的系数去消除以分组数据基数差异所造成的影响。同时必须了解清楚情况,是否存在潜在因素,综合考虑。
作者:云创智学 来源:云创智学
发布时间:2021-11-10 13:24:50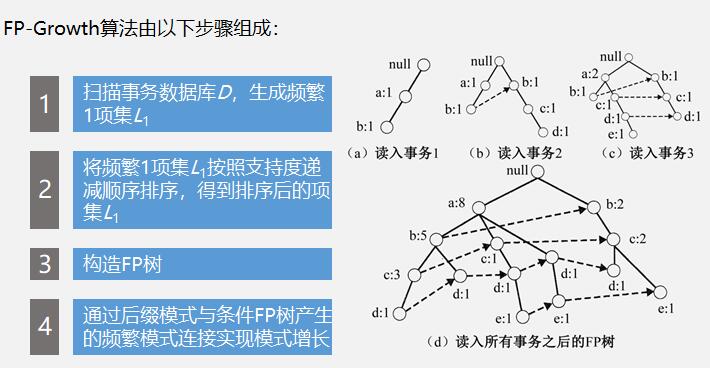
数据挖掘算法之 关联规则是什么意思
关联规则是数据挖掘中最活跃的研究方法之一,是指搜索业务系统中的所有细节或事务,找出所有能把一组事件或数据项与另一组事件或数据项联系起来的规则,以获得存在于数据库中的不为人知的或不能确定的信息,它侧重于确定数据中不同领域之间的联系,也是在无指导学习系统中挖掘本地模式的最普通形式。应用市场:市场货篮分析、交叉销售(CrossingSale)、部分分类(PartialClassification)、金融服务(FinancialService),以及通信、互联网、电子商务······关联规则的概念:一般来说,关联规则挖掘是指从一个大型的数据集(Dataset)发现有趣的关联(Association)或相关关系(Correlation),即从数据集中识别出频繁出现的属性值集(SetsofAttributeValues),也称为频繁项集(FrequentItemsets,频繁集),然后利用这些频繁项集创建描述关联关系的规则的过程。关联规则挖掘问题:如何迅速高效地发现所有频繁项集,是关联规则挖掘的核心问题,也是衡量关联规则挖掘算法效率的重要标准。
作者:云创智学 来源:云创智学
发布时间:2021-11-09 10:42:03
 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信