




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

人工智能的未来发展应用的前景
人工智能的未来发展应用的前景:人工智能一直处于计算机技术的前沿,计算机技术的发展方向将很大程度上依赖人工智能理论方面的研究和发现。人工智能对现代社会已经产生了巨大的影响,在工业领域尤其是制造业,已经成功地使用了人工智能技术,例如,智能设计、在线分析、仿真、虚拟制造、智能调度和规划等。在金融业,股票商利用人工智能系统进行分析、判断和决策,信用卡欺诈检测系统也得到了普遍应用;在传媒领域,新华网推出了自主研发的第一代生物传感智能机器人“Star”。人工智能还对人们的日常生活产生了影响,Siri、实时在线地图、语音搜索等一系列智能产品已经给我们的生活带来了极大的方便。未来应该是一个人工智能的世界。一朵花可能拥有智能,根据主人的心情来开放;每个人都有一个智能伴侣,让我们更加理性地购物;甚至还能帮助信徒决定他们的人生信仰等。未来的人工智能将很多领域代替人类,并能服务我们人类自身,处理我们日常的生活。1、人工智能结合数据协助医生诊断病症;2、人工智能操作家用电器,人工智能汽车还可以经预测降低交通事故的发生率;3、在极端的施工场地承担危险的工作,帮助人类降低伤亡的风险;4、帮助人类从事诗歌写作、绘画艺术等复杂的精神活动。
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-11-19 09:58:38
发布时间:2021-11-19 09:58:38大数据与深度学习关系
2006年Hinton等人提出深度学习的概念,该方法基于深度置信网络提出非监督逐层训练的算法,为解决深层结构相关的优化难题带来了希望,掀起了深度学习在学术界和工业界的浪潮。随着CPU和GPU计算能力的大幅提升,深度学习拥有了的更高效的硬件平台作为支撑。大数据时代的海量数据解决了早期神经网络由于训练样本不足出现的过拟合、泛化能力差等问题。因此,大数据需要深度学习,深度学习的发展又需要大数据的支撑。在未来几年,深度学习将会被广泛应用于大数据的预测,而不是停留在浅层模型上,这将推动“大数据+深度模型”时代的来临,以及人工智能和人机交互的前进步伐。
作者:云创智学 来源:云创智学
发布时间:2021-11-19 09:56:04人工智能发展史介绍
人工智能发展三个阶段:1、20世纪40年代中期到50年代末期被称为人工智能的启蒙探索阶段。2、20世纪60年代初期到80年代末期被称为人工智能的发展阶段。3、20世纪90年代初期到现在被称为人工智能的繁荣阶段。20世纪40年代中期到50年代末期,人工智能的启蒙探索阶段1950年,英国数学家图灵在论文《计算的机器与智能》为计算机的出现奠定了理论基础。同时期,W.McCullocli和W.Pitts发表了《神经活动内在概念的逻辑演算》,证明了可以严格定义的神经网络。1956年,美国达特茅斯大学的一次暑期专题研讨会上第一次提出了人工智能,开创了人工智能的这一研究领域。1957年,A.Newell和H.Simon等人编写了逻辑理论机的数学定理证明的程序,该程序证明了《数学原理》书中的38个定理。1956年Samuel编写的西洋跳棋程序,到1959年这个程序战胜了他本人,1962年还击败了美国Connecticut州的跳棋冠军。20世纪60年代初期到80年代末期,人工智能的发展阶段1968年,第一个用于质谱仪分析有机化合物的分子结构的专家系统DENDRAL研制成功。20世纪70年代初,Winograd提出了积木世界中理解自然语言的程序等。1974年,N.J.Nillson对之前的一些工作进行了综述,并写了一篇论文,把对人工智能的研究归纳为4个核心课题。1980年早期,人工智能的研究者研究出了专家系统,并产生了巨大的经济效益。1982年日本开始了使得逻辑推理与数值运算一样快的第五代计算机的研制计划。1986年,Rumelhart提出了反向传播算法,用以解决人工神经元网络的学习问题,进而人们进一步转向对人工神经元的研究。1987年,第一次神经网络国际会议在美国召开,宣告了这一新学科的诞生。20世纪90年代初期至今,人工智能的繁荣阶段1997年IBM公司研制了“深蓝计算机”,首次在正式比赛中以3.5∶2.5的比分战胜了人类国际象棋世界冠军。2016年3月15日,谷歌人工智能AlphaGo与围棋世界冠军李世石的人机大战,最终李世石与AlphaGo以1∶4认输结束。
作者:云创智学 来源:云创智学
发布时间:2021-11-19 09:54:04
深度学习概念,深度学习是什么
深度学习概念:深度学习(DeepLearning)的概念是由Hinton、YoshuaBengio和YannLecun等人提出的,涉及神经网络、图建模、人工智能、模式识别、最优化理论和信号处理等领域。由于深度学习在各类竞赛中,相对于传统方法有着显著的性能提升,越来越多的学术机构和企业把目光转向了深度学习领域。例如:2010年美国国防部DARPA首次资助深度学习项目;2012年11月,微软在天津展示了全自动同声传译系统,用英文演讲,采用深度学习作为支撑,后台计算机自动完成了语音识别、中英机器翻译和中文语音合成;2013年1月,百度创始人宣布成立百度研究院,其中第一个成立的就是“深度学习研究所”;2013年4月,《麻省理工学院技术评论》杂志将深度学习列为2013年十大突破性技术之首。
作者:云创智学 来源:云创智学
发布时间:2021-11-19 09:44:49SparkR实现的主要机器学习算法概述
SparkR实现的主要机器学习算法概述:广义线性模型广义线性模型:简单最小二乘回归(OLS)的扩展,响应变量可以是正整数或分类数据,为某指数分布族,期望值函数与预测变量之间为线性关系,需要指定分布类型和连接函数。加速失效时间生存回归模型:AFT模型将经典线性回归模型的建模方法直接拓展到了生存分析领域,即具有截尾生存时间的情形。朴素贝叶斯模型:通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,选择具有最大后验概率的类作为该对象所属的类。K-means模型:SparkR提供了对K-means算法的支持,K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标。模型的保存与加载:模型训练好了以后,需要将训练好的模型保存起来,以便下一次再用。
作者:云创智学 来源:云创智学
发布时间:2021-11-18 13:27:54SparkR与HQL应用
HQL是一种类SQL的语言,这种语言最终被转化为Map/Reduce,通过Hive可以使用HQL语言查询存放在HDFS上的数据。SparkR:利用Hive表来创建DataFrame;将DataFrame转化为SparkSQL;SparkR提供了对HQL的支持和API,但是Hive适合用来对一段时间内的数据进行分析查询。
作者:云创智学 来源:云创智学
发布时间:2021-11-18 13:25:14SparkR 使用方法
环境搭建:1.Linux下安装R首先在官网下载R的软件包,官网网址为http://cran.rstudio.com/2.rJava包安装SparkR包对rJava包有依赖关系,因此,在安装SparkR之前,需要先完成rJava包的安装3.SparkR的安装为了避免Spark版本的兼容问题,采用源码编译的方式来安装SparkRSparkR使用方法:创建SparkSession:SparkSession(即Spark会话)是SparkR的切入点,它使得R程序和Spark集群相互通信。创建SparkDataFrmes:根据需要从本地R数据框(Rdataframe),Hive表(Hivetable)或者从其他数据源创建SparkDataFrmes
作者:云创智学 来源:云创智学
发布时间:2021-11-18 11:16:56SparkR介绍和优点
SparkR介绍:SparkR就是用R语言编写Spark程序,它允许数据科学家分析大规模的数据集,并通过RShell交互式地在SparkR上运行作业上。SparkR的核心是SparkRDataFrame,数据组织成一个带有列名的分布式数据集。SparkR优点:1、taFrames的数据来源非常广泛;2、高扩展性;3、DataFrames的优化;4、对RDDAPI的支持。
作者:云创智学 来源:云创智学
发布时间:2021-11-18 11:12:37R语言与数据挖掘应用实战实例
R语言与数据挖掘应用实战实例:背景:河流中海藻的集中爆发不仅会对河流的生态环境造成破坏,还会影响河流的水质;需求:基于以往的观测数据,对河流中海藻的爆发情况进行预测并采取必要防范措施以提高河流的水质量;方法:以海藻样本数据为数据集,通过数据挖掘的方式分析影响海藻爆发的主要因素,并通过构建预测模型,对海藻的爆发情况进行事先预测。部分代码:线性回归和回归树模型的预测>lm.predictions.a1<-predict(final.lm,clean.algae)#计算线性回归模型的预测值>rt.predictions.a1<-predict(rt.a1,algae)#计算回归树模型的预测值>mae.a1.lm<-mean(abs(lm.predictions.a1-algae[,"a1"]))#计算预测值的平均误差>mae.a1.rt<-mean(abs(rt.predictions.a1-algae[,"a1"]))#计算预测值的平均误差>mae.a1.lm#显示线性回归模型预测值的平均误差[1]13.10681>mae.a1.rt#显示回归树模型预测值的平均误差[1]8.480619回归树的MAE值为8.48线性回归模型的MAE值13.11回归树模型的预测值的平均误差要优于线性回归模型预测值的平均误差
作者:云创智学 来源:云创智学
发布时间:2021-11-18 11:06:59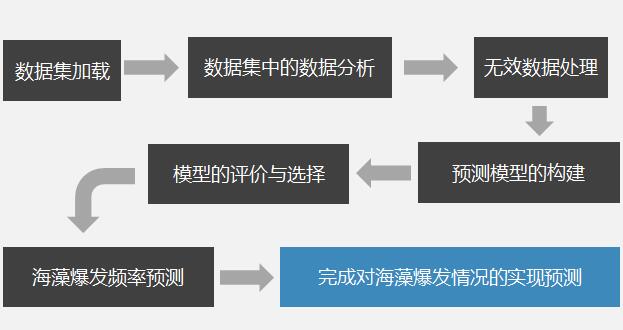
R语言分类与预测算法有哪些
R语言分类与预测算法有哪些:1、分类与预测算法—K-近邻算法:如果一个样本与特征空间中的K个最相似(特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。2、分类与预测算法—决策树决策树(DecisionTree)是一种依托于分类、训练上的预测树,根据已知预测、归类未来。3、分类与预测算法—支持向量机:支持向量机(SupportVectorMachine,SVM)是一个二分类的办法,即将数据集中的数据分为两类。4、聚类算法及其R包“聚类”是根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组(或称为簇),并对每个簇进行描述的过程。常用的聚类算法主要包括K-means聚类、层次聚类和基于密度的聚类5、聚类算法及其R包—K-means聚类同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小6、聚类算法及其R包—层次聚类一层一层地进行聚类,可以从下而上地把小的cluster合并聚集,也可以从上而下地将大的cluster进行分割。7、聚类算法及其R包—基于密度的聚类8、离群点检测与R包9、关联规则与R包10、时间序列分类与R包11、文本挖掘提取文本中的词语,并统计频率
作者:云创智学 来源:云创智学
发布时间:2021-11-17 17:52:29

 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信