




- 0
用户访问量
- 0
注册用户数
- 0
在线视频观看人次
- 0
在线实验人次

R语言与数据挖掘介绍
一、数据挖掘:数据挖掘(DataMining)是从大量的数据中发现有趣知识的过程,涉及统计学、机器学习、模式识别等多个交叉;主要技术包括分类与预测、聚类、离群点检测、关联规则、序列分析和文本挖掘以及社交网络分析和情感分析等。二、R语言与数据挖掘有关的任务视图1、MachineLearning:主要涉及机器学习和统计学习功能2、Cluster:主要涉及聚类分析和有限混合模型3、TimeSeries:主要涉及时间序列分析4、Multivariate:主要用于多元统计分析及其算法5、Spatial:主要用于空间数据分析R语言主要用于统计计算和统计制图,提供了大量的统计和制图工具
 作者:云创智学
作者:云创智学  来源:云创智学
来源:云创智学
 发布时间:2021-11-17 17:38:31
发布时间:2021-11-17 17:38:31R语言是什么?R语言简介
一、R语言产生与发展历程不单是一门语言,更是一个数据计算与分析的环境,内容涵盖了从统计计算到机器学习,从金融分析到生物信息,从社会网络分析到自然语言处理,从各种数据库各种语言接口到高性能计算模型。二、R语言基本功能介绍R语言是一套完整的数据处理、计算和制图软件系统,主要包括以下功能:1、数据存储和处理系统2、数组运算工具,(其向量、矩阵运算方面功能尤其强大)3、完整连贯的统计分析工具4、优秀的统计制图功能三、丰富的数据读取和存储能力1、可以保存和加载R语言的数据,与R.data的交互是通过R语言的save()函数和load()函数实现的2、能够加载和导出.csv文件(write.csv()函数和read.csv()函数)3、能够导入SPSS/SAS/Matlab等数据集4、可以通过RODBC接口,从数据库中导入数据5、可以通过odbcConnectExcel接口从Excel表格中导入数据数据挖掘中,需要花70%以上的时间在数据处理上,R语言提供丰富的数据处理功能筛选:filter()按给定的逻辑判断筛选出符合要求的子数据集排列:arrange()按给定的列名依次对行进行排序选择:select()用列名作参数来选择子数据集变形:mutate()或transformation()用来进行列变形汇总:summarise()进行汇总操作,返回一维结果分组:分组动作group_by()向量:R语言处理数据的最基本单位是向量,而不是原子数据;因子:R语言定义了一类非常特殊的数据类型:因子;数组:数组是向量和矩阵的直接推广,是由三维或三维以上的数据构成的;矩阵:较复杂的继承关系,和数组的关系既是父亲又是儿子,还是孙子;列表:列表由向量直接派生而来;数据框:可以将几个不同类型但长度相同的向量合并到一个数据框;特殊值数据:定义了如NULL、NA、NaN、inf等特殊数据;有用函数:提供了获取数据类型信息的一些有用函数。四、R语言常见的应用领域
作者:云创智学 来源:云创智学
发布时间:2021-11-17 17:35:34
十大热门编程语言第七位R语言
R语言用于:1、用于统计计算和作图的语言;2、免费、开源及统计模块齐全;3、数据挖掘、机器学习、自然语言处理等;4、计量经济学、实证金融学、统计遗传学等。
作者:云创智学 来源:云创智学
发布时间:2021-11-17 17:30:00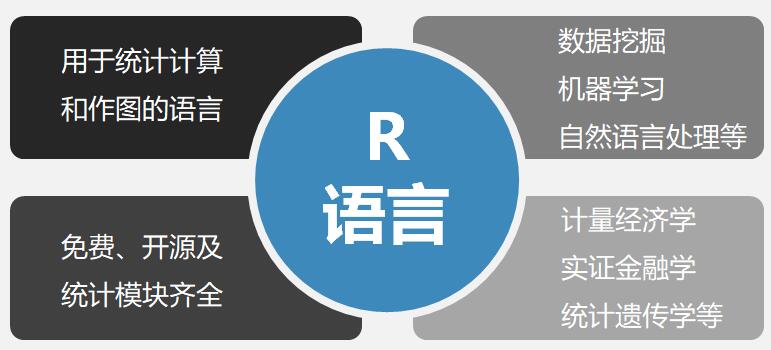
阿里数据挖掘平台DT PAI
DTPAI基于阿里云大数据处理平台ODPS构建,集成了阿里巴巴核心智能算法库,包括特征工程、数据探查与统计、大规模机器学习、深度学习,以及阿里在文本、图像和语音处理方面的数据技术。图形化编程、数据分析挖掘、用户行为预测、行业走势预测
作者:云创智学 来源:云创智学
发布时间:2021-11-17 17:20:56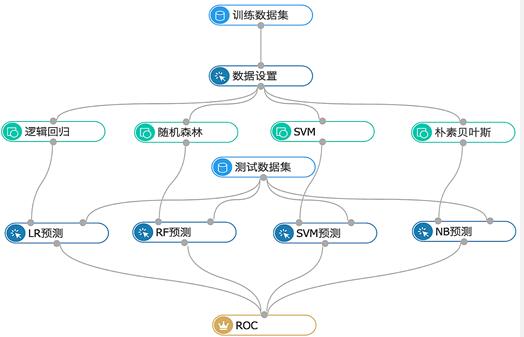
百度大规模机器学习框架ELF与机器学习云平台BML
百度大规模机器学习框架ELF与机器学习云平台BML:ELF:大规模分布式机器学习框架,基于ParameterServer模型的通用化大规模机器学习系统。ELF(EssentialLearningFramework)特点:吸收了Hadoop、Spark和MPI等大数据平台的优点,用类似于Spark的全内存DAG计算引擎,可基于数据流的编程模式,通过高度抽象的编程接口,让用户方便地完成各种机器学习算法的并行化设计和快速计算。BML:大规模并行化机器学习处理,用于微信语音和图像识别的深度学习平台。BML(BaiduMachineLearning)特点:支持数据预处理算法、分类算法、聚类算法、深度学习等20多种机器学习算法,通过分布和并行化计算实现优异的计算性能,承载百度公司如网页搜索、百度推广(凤巢、网盟CTR预估)、百度地图、百度翻译等业务应用。
作者:云创智学 来源:云创智学
发布时间:2021-11-16 11:41:34
腾讯大规模主题模型训练系统Peacock与深度学习平台Mariana
腾讯大规模主题模型训练系统Peacock与深度学习平台Mariana:Peacock:大规模LDA主题模型训练系统,用于语义理解、兴趣挖掘、用户拓展、QQ群推荐等。特点:1、大规模样本数据处理;2、大规模矩阵分解;3、隐含语义学习Mariana:大规模并行化机器学习处理,用于微信语音和图像识别的深度学习平台。Mariana特点:1、多GPU的深度神经网络并行计算系统MarianaDNN;2、CPU集群的深度神经网络并行计算系统MarianaCluster;3、多GPU的深度卷积神经网络并行计算系统MarianaCNN
作者:云创智学 来源:云创智学
发布时间:2021-11-16 11:37:15scikit-learn数据挖掘工具主要模块和支持的算法
scikit-learn数据挖掘工具主要模块和支持的算法:基于Python的机器学习库,建立在NumPy、SciPy和matplotlib基础之上,使用BSD开源许可证。主要模块:分类、回归、聚类、数据降维、模型选择、数据预处理。支持算法:SVM、K-Means、SVR、Lasso、randomforest等。
作者:云创智学 来源:云创智学
发布时间:2021-11-16 11:29:47
Parameter server 数据挖掘工具推理
Parameterserver数据挖掘工具:基于模型参数的抽象方法,即把所有机器学习算法抽象为对学习过程中一组模型参数的管理和控制,并提供对大规模场景下大量模型参数的有效管理和访问。适用:机器学习算法研究者、深度优化机器学习算法的数据分析程序员。有点:为大规模机器学习提供了非常灵活的模型参数调优和控制机制。缺点:缺少对大规模机器学习时的数据及编程计算模型的高层抽象。
作者:云创智学 来源:云创智学
发布时间:2021-11-16 11:22:56
GraphLab 数据挖掘工具原理
GraphLab数据挖掘工具:卡内基梅隆大学的Select实验室开发的以顶点为计算单元的大规模图处理系统,是一个基于图模型抽象的可扩展的机器学习框架
作者:云创智学 来源:云创智学
发布时间:2021-11-16 11:19:21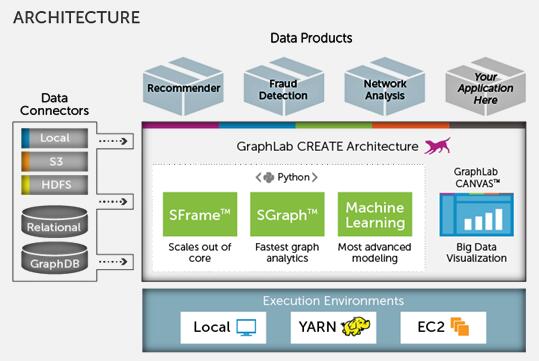
spark Mllib协同过滤算法
sparkMllib协同过滤算法:MLlib中支持的是基于模型的协同过滤,即交替最小二乘(ALS)算法依旧以4.1.4节中用户物品数据为例:1、先加载了训练数据文件,然后解析每行数据,并将其转换为Rating对象2、定义特征矩阵的维度rank和算法迭代次数numIterations3、调用ALS的类方法train(),根据训练数据ratings学习出评分模型4、调用recommendProductsForUsers()向用户推荐指定个数的物品
作者:云创智学 来源:云创智学
发布时间:2021-11-15 15:15:29
 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座


联系我们
服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)
联系方式

企业微信